Ver código
#install.packages("tidyverse")
library(tidyverse)
#install.packages('eph')
library(eph)
options(scipen = 999)
Compartir el código es esencial para mejorar la calidad de nuestras prácticas en ciencias sociales y para asegurar que los resultados de nuestros trabajos sean confiables, transparentes y reproducibles. Aún más, supone un posicionamiento ético profesional frente a la forma en construimos y transmitimos conocimiento1.
A propósito de ello, recientemente surgió en un grupo de chat de profesionales de ciencia de datos en el que participo, la consulta a propósito cómo calcular el coeficiente de Gini, tomando como unidad de análisis la EPH. Lo cierto es que tenía el código a mano, ya que lo había calculado hace algo más de un año, en ocasión de una consultoría internacional, pero, entre la vorágine de la vida profesional y los múltiples atractores que ofrece la contemporaneidad, nunca llegué a publicarlo y compartirlo, con lo cual aprovecho este momento de vacaciones (en Argentina), junto al protector solar factor 50 y los maravillosos churros de la costa argentina, para hacerlo.
Al mencionar en el título de este documento que podemos calcular el indice de Gini en casa, se afirma una tesis desfetichizante con respecto a las herramientas tecnológicas de programación disponibles en la actualidad, la cual estará presente a lo largo de este documento, y que establece que el avance de la tecnología y el acceso al conocimiento, producto de la cuarta revolución industrial, coadyuvan a que cualquier profesional de las ciencias sociales con conocimiento de dominio pueda programar un índice como el de Gini, y que las acciones técnicas requeridas para tal fin se encuentran objetivamente al alcance de un click.
Ahora sí, retomemos.
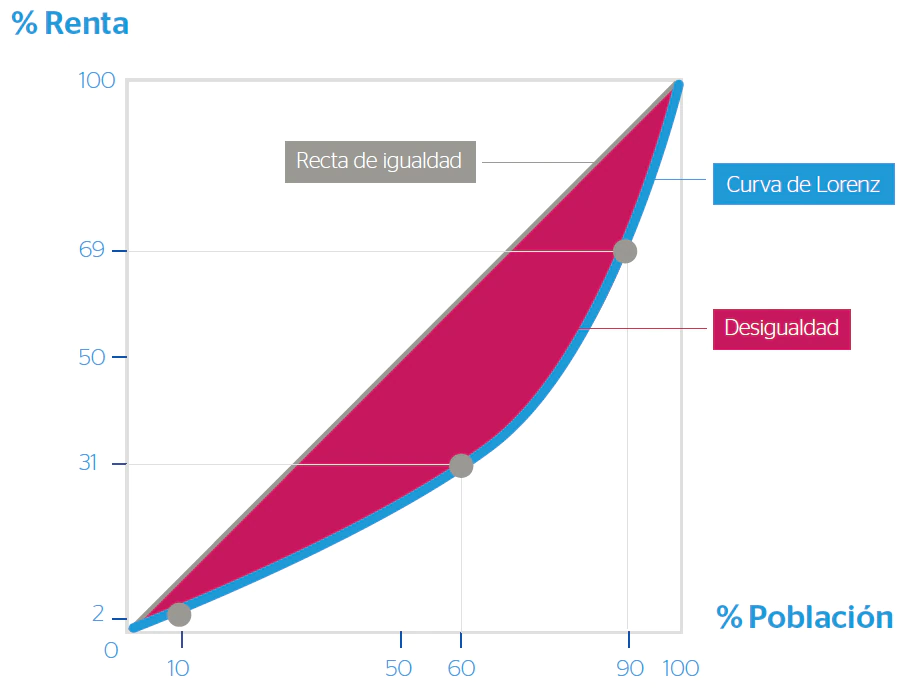
El coeficiente de Gini es una medida de desigualdad económica, utilizada de manera frecuente por estar en asociación con la curva de Lorenz; por medio de la cual se establece la distribución teórica que debería tener una variable si se repartiese por igual entre todas las unidades.
Siguiendo a Salvia et al (2005)2 el coeficiente de Gini opera comparando dos distribuciones: la empírica y la que se deriva de la aplicación del concepto de equidistribución.
En este sentido, el valor mínimo del índice es cero y se alcanza siempre que la variable se distribuya “democráticamente” entre todas las unidades (en este caso, la distribución empírica será similar a la curva de Lorenz indicando una distribución perfectamente igualitaria.
Su valor máximo es uno, y se llega a él cuando el valor total de una variable le corresponde sólo a una de las observaciones (o estratos, en el caso de trabajar con datos agrupados).
Veamos un resumen gráfico de lo mencionado:
Para calcular el coeficiente utilizaremos la siguiente fórmula:
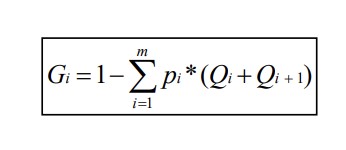
Para llevar adelante la tarea de calcular el indice de Gini en base a los datos de la EPH, realizaremos primero un sucinto ETL orientado descargar las bases del INDEC y ajustarlas a nuestro objetivo de trabajo.
Vamos a utilizar los paquetes tidyverse para manipular datos con R y eph, un desarrollo notable de industria nacional, made in el campo de las ciencias sociales, que disponibiliza los microdatos de la encuesta y provee ademas funciones para ordenarlos, transformarlas, etc.
#install.packages("tidyverse")
library(tidyverse)
#install.packages('eph')
library(eph)
options(scipen = 999)A la fecha el INDEC publica en Evolución de la Distribución del Ingreso4 la serie temporal del coeficiente de Gini desde 2018 hasta el segundo trimestre de 2022:
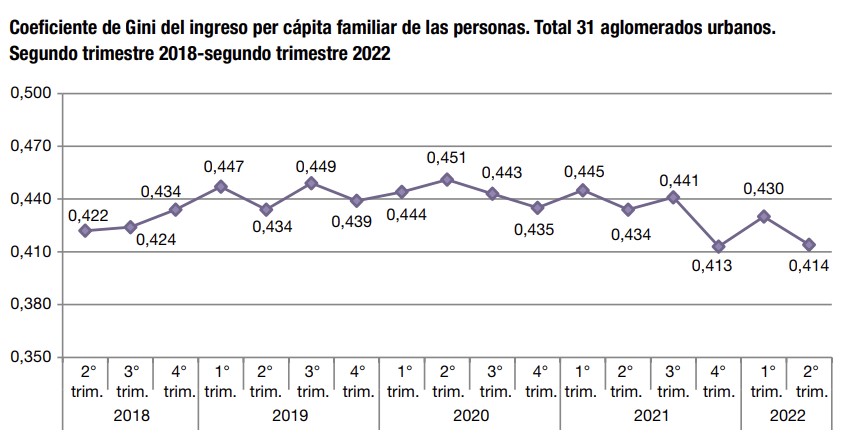
Por tanto nuestro objetivo va a ser replicar este cálculo para el total de los 31 aglomerados en nuestra PC, con las herramientas opensource que nos provee R.
Descarguemos entonces las bases correspondientes a individuos y hogares de 2018 a la fecha.
#esta acción puede tardar un rato porque vamos a descargar bases pesadas
bases_individuo <- get_microdata(year = 2018:2022,
trimester = 1:4,
type = 'individual')
baseshog <- get_microdata(year = 2018:2022,
trimester = 1:4,
type = 'hogar',
vars = c("ANO4","TRIMESTRE","REGION", "AGLOMERADO",
"CODUSU", "NRO_HOGAR","IX_TOT","II1"))
#el visor nos va a decir que hubieron algunos errores en la descarga de datos, no tenemos que prestarle atención.Uniremos las bases de hogares e individuos, puesto que lo que nos interesa en este punto es recalcular el ingreso per cápita familiar, el dato de ingreso clave para la estimación del índice.
Si bien en los microdatos de individuos del INDEC existe la variable de ingreso per cápita familiar y se denomina IPCF, la misma presenta inconsistencias que salvamos recalculándola en una nueva variable llamada IPCF2, mediante la división simple del ingreso total de los hogares entre el número de personas que lo conforman.
bases_total<-baseshog%>%
full_join(bases_individuo)
# La línea de código está realizando una unión completa (full_join) entre dos dataframes, "baseshog" y "bases_individuo", y guardando el resultado en un nuevo dataframe llamado "bases_total".
bases_total <- bases_total%>%
mutate(IPCF2 = round(ITF / IX_TOT, digits = 2))%>% #recalculamos IPCF porque la variable de la base presenta errores. Creamos ipcf2
filter(!CODUSU %in% c("TQSMNORWVHMOKOCDEGLDF00700688",
"TQSMNORWVHMOKOCDEGLDF00700688")) #filtramos dos filas que tienen errores de tipeo.Para que no queden dudas exploremos más sobre la variable IPCF original. Vamos a generar con nuestro código una alerta que indique cuando IPCF e IPFC2 difieren.
comparacion <- bases_total%>%
select(ANO4, TRIMESTRE, IX_TOT, ITF, IPCF2, IPCF)%>%
unique()%>%
mutate(alerta=case_when(IPCF==IPCF2~"ok",#si IPCF no es igual a IPCF2 r nos avisa
IPCF>IPCF2~"mal",
IPCF<IPCF2~"mal"))%>%
mutate(diferencia=IPCF-IPCF2)
#imprimidos las 10 diferencias más grandes
comparacion%>%
filter(alerta=="mal")%>%
arrange(desc(diferencia))%>%
head(10)# A tibble: 10 x 8
ANO4 TRIMESTRE IX_TOT ITF IPCF2 IPCF alerta diferencia
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
1 2020 3 3 691400 230467. 23046667 mal 22816200.
2 2020 3 3 400000 133333. 13333333 mal 13200000.
3 2020 3 3 320000 106667. 10666667 mal 10560000.
4 2020 3 3 310000 103333. 10333333 mal 10230000.
5 2020 3 3 295000 98333. 9833333 mal 9735000.
6 2020 3 3 280000 93333. 9333333 mal 9240000.
7 2020 3 3 263000 87667. 8766667 mal 8679000.
8 2020 3 3 260000 86667. 8666667 mal 8580000.
9 2020 3 3 242000 80667. 8066667 mal 7986000.
10 2020 3 6 470000 78333. 7833333 mal 7755000.Lo que podemos intuir acerca de los errores mas grandes que es que durante el proceso de carga de los datos pudo haber habido un error que derivó en la eliminación del punto separador de dos decimales.
Ploteamos las diferencias para ver en que período se concentran:
comparacion%>%
ggplot() +
aes(x = diferencia) +
geom_histogram(bins = 30L, fill = "#112446") +
theme_minimal() +
facet_wrap(vars(ANO4))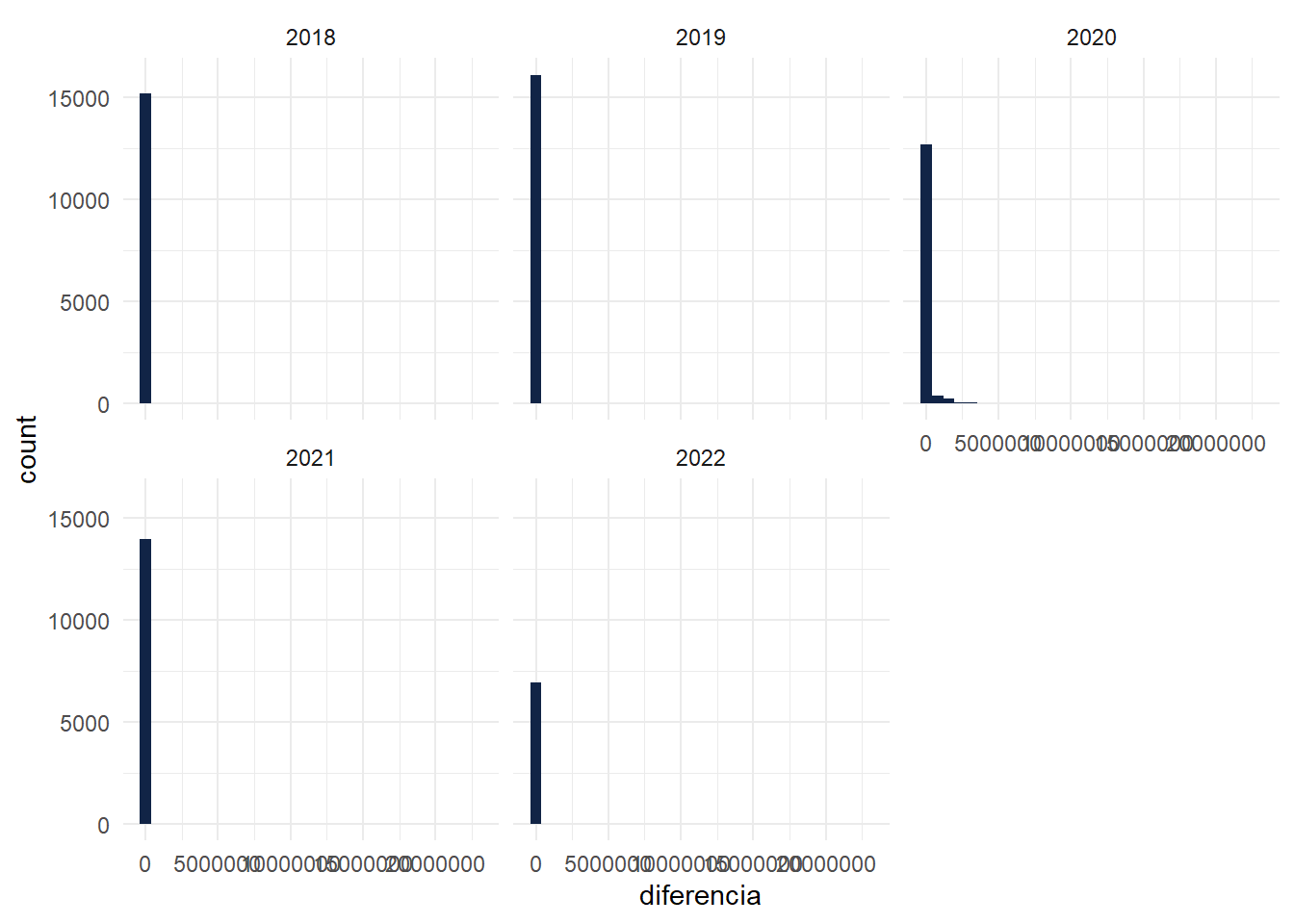
Por lo general se corresponde a errores de carga o formato ocurridos en 2020, un año complejo para todos y todas.
En este caso, lo importante es que contamos con los datos completos como para recrear nuestra variable de interés y sobre todo que pudimos hacerlo sin mayores inconvenientes.
Con nuestro marco de datos de la eph completo, vamos calcular ahora sí el coeficiente de Gini.
Para ello, lo calculamos en la variable gn.nac, que es un summarise en el cual aplicamos la función gini de la librería reldist al ingreso medio familiar (IPCF2) ponderado por su correspondiente factor PONDIH.
library(reldist)
Gini_nacional <- bases_total%>%
select(ANO4, TRIMESTRE, IPCF2, PONDIH) %>% #Seleccionamos las variables de interes y agrupamos por a?o y cuatrimestre
group_by(ANO4, TRIMESTRE) %>% # agrupamos por a?o y trimestre para emular al indec
summarise(gn.nac= gini(IPCF2, weights= PONDIH)) %>% #aplicamos la funci?n Gini y usamos el factor de expansi?n PONDIH (Ponderador del ingreso total familiar y del ingreso per c?pita familiar, para hogares)
ungroup() #des agrupamos
glimpse(Gini_nacional)Rows: 18
Columns: 3
$ ANO4 <dbl> 2018, 2018, 2018, 2018, 2019, 2019, 2019, 2019, 2020, 2020, ~
$ TRIMESTRE <dbl> 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2
$ gn.nac <dbl> 0.4397292, 0.4220539, 0.4237804, 0.4342749, 0.4468784, 0.433~Hecho! ya generamos los valores del coeficiente de Gini por año y trimestre.
Para finalizar hagamos un gráfico y comparemos nuestros datos con los del INDEC.
#esquisse::esquisser(Gini_nacional)
library(lubridate)
Gini_nacional<-Gini_nacional%>%
mutate(periodo = as_date(parse_date_time(paste0(ANO4,'-',TRIMESTRE), 'Y.q')))
Gini_nacional %>%
filter(!periodo=="2018-01-01")%>%
ggplot(aes(x = periodo, y = gn.nac )) +
geom_line(size = 1.9, alpha = 0.4, color="#9977BB")+
geom_point(size = 4, alpha = 0.5, shape=18, color="#6b5382")+
scale_x_date(date_labels="%m %Y", date_breaks ="3 month")+
labs(title = "Coeficiente de Gini en Argentina.",
subtitle = "Período: 2t de 2018 a 2t de 2022.",
x= "",
y= "Gini",
caption = "Fuente: elaboración propia en base a datos de EPH-INDEC.")+
theme_bw() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))+
geom_text(aes(label = sprintf("%.3f", gn.nac)),
size = 2.5, hjust = 0.1,
fontface = "bold",
vjust =1.2, position = "stack",
show.legend = FALSE)+
coord_cartesian(ylim = c(0.3, 0.5))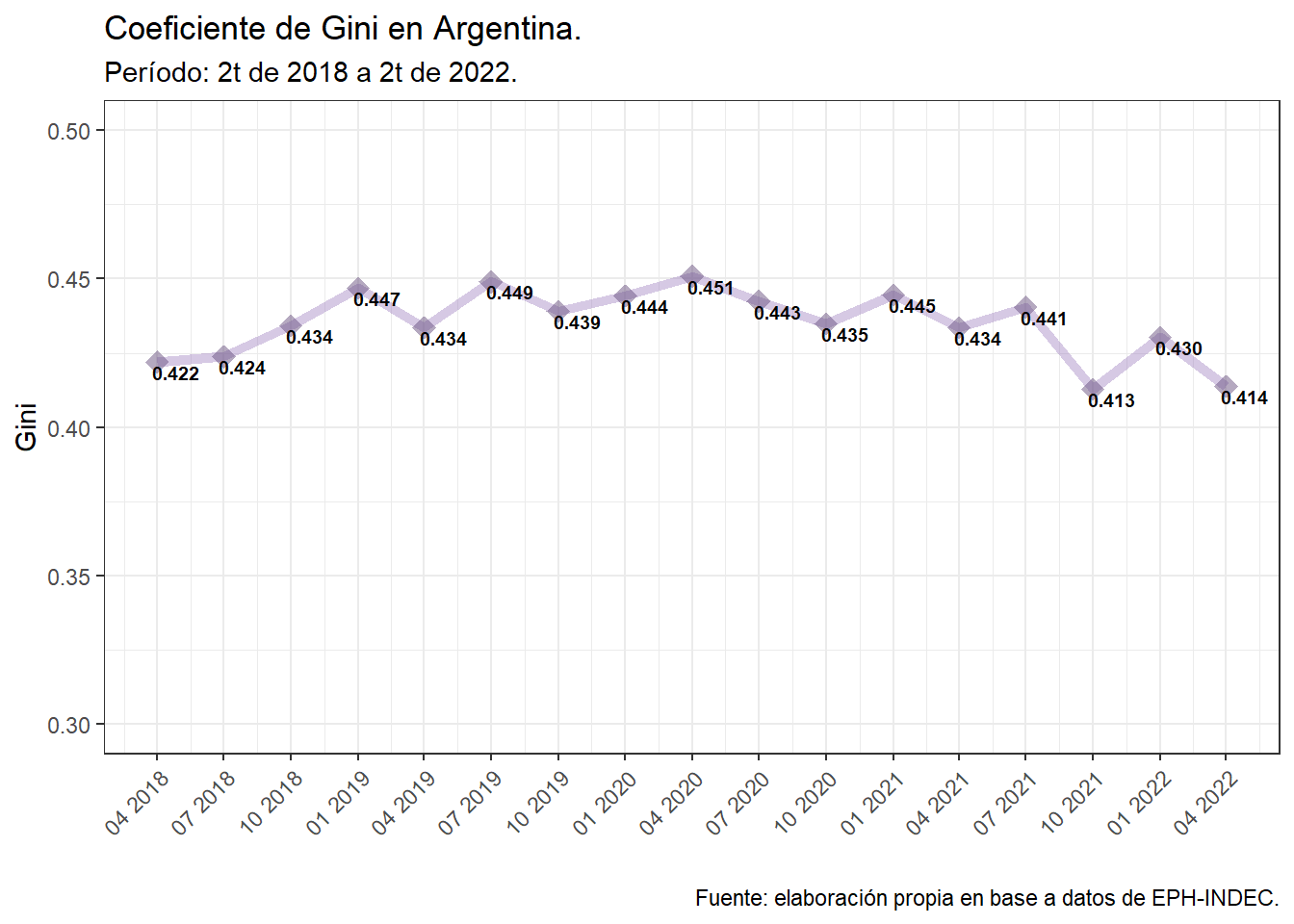
A modo de ejercicio de cierre, la conclusión preliminar que podríamos sacar leyendo sólo este gráfico es que durante el período de pandemia en Argentina existió un aumento moderado de desigualdad por ingreso, que se inicio tiempo antes. Según nuestros datos, el alza sostenida del coeficiente de Gini comienza en 2018 y se mantiene hasta 2021 donde hacia mediados de dicho año perfora el piso de .440 que hasta el momento se mantenía como punto de soporte.
Para finalizar rearmé el módulo original que hice tiempo atrás en una shiny , la cual muestra interactivamente los datos del coeficiente a escala nacional, regional y de aglomerado por año y trimestre.
Si te interesa utilizar esta app en pantalla completa podés hacerlo acá.
En este artículo hemos revisado cómo confeccionar el índice de Gini en R, un lenguaje de programación ampliamente utilizado en el análisis estadístico y en particular el análisis de datos. En este sentido, proporcionamos un tutorial paso a paso sobre cómo calcular el coeficiente, incluyendo códigos de ejemplo y explicaciones paso a paso.
Además, destacamos la importancia del código abierto, ya que nos permite a los profesionales e investigadores compartir, colaborar y mejorar con el avance del conocimiento social de manera transparente. La transparencia, la colaboración y la mejora continua son fundamentales en el campo de la investigación basada en evidencia y la análisis estadístico.
En un mundo atravesado por la innovación permanente es clave mantenerse actualizado profesionalmente, puesto que la tecnología y los métodos de análisis de datos están en constante evolución. En este sentido, la formación técnica continua y la participación en comunidades de profesionales son esenciales para mejorar las habilidades y conocimientos necesarios para trabajar con datos abiertos y código abierto.
Enero 2023
Pedro Damián Orden (Licenciado en Sociología (UBA), matrícula nacional N° 1022, matrícula provincial N° 304).
Compartir lo que sabemos con otros y otras contribuye sin dudas a la mejora social.↩︎
Salvia, Agustín, Metlika, U. y Vera, J. (Diciembre, 2004). La desigualdad social en la Argentina. Un enfoque regional. II Congreso Nacional de Sociología. Pre ALAS 2005, Buenos Aires.↩︎
La observación de Cortés y Rubalcava (1984) resule varios de los debates puesto que los autores si bien reconocen que el índice cumple con la condición de Pigou – Dalton, resulta generalista e insensible a las redistribuciones que se llevan a cabo entre observaciones que se encuentran a igual distancia en la ordenación. Ello supondrá que el coeficiente no daría cuenta acabada de las diferencias en cuanto al nivel que se realiza la redistribución; sino que el cambio en su valor se relaciona sólo con la distancia entre las unidades involucradas.↩︎
Ver https://www.indec.gob.ar/uploads/informesdeprensa/ingresos_2trim22BF474C3CB1.pdf↩︎
@online{damián_orden2023,
author = {Damián Orden, Pedro},
title = {Calculando El Coeficiente de {Gini} En Casa},
date = {2023-01-16},
url = {https://tecysoc.netlify.app/posts/gini-eph/},
langid = {en}
}