Ver código
#cargamos librerias necesarias para la clase
library(tidyverse)
library(tidytext)
library(rvest)
library(stopwords)
#install.packages("udpipe")
library(udpipe)
library(lattice)
#install.packages("glue")
library(glue)
El presente documento electrónico es una primera revision del material de cursada del seminario de Introducción a la Investigación con Estrategias Computacionales de la Carrera de Sociología de la Universidad de Buenos Aires (UBA).
Este seminario de investigación tiene como objetivo proporcionar a los estudiantes la oportunidad de aplicar técnicas y tecnologías computacionales en casos reales de investigación en la sociología clásica. Al integrar métodos computacionales avanzados, como el scraping y la lematización, los estudiantes pueden complementar sus enfoques tradicionales con herramientas que les permitan analizar grandes volúmenes de datos de manera eficiente y precisa.
El scraping, por ejemplo, facilita la recolección automatizada de datos desde diversas fuentes web, mientras que la lematización permite la normalización y simplificación del texto, mejorando la precisión de los análisis lingüísticos. Estas técnicas son de suma utilidad para los investigadores sociales, ya que les permiten obtener y procesar información de manera más efectiva.
Compartir este material de manera open source refuerza nuestro compromiso con la difusión de conocimiento libre y de calidad generado desde la universidad pública en Argentina. Al hacerlo, promovemos el acceso a recursos educativos esenciales para una amplia comunidad de estudiantes, investigadores y profesionales, fomentando la colaboración y el intercambio de saberes en el ámbito de las ciencias sociales.
#cargamos librerias necesarias para la clase
library(tidyverse)
library(tidytext)
library(rvest)
library(stopwords)
#install.packages("udpipe")
library(udpipe)
library(lattice)
#install.packages("glue")
library(glue)En esta clase continuaremos explorando los procesos extracción, procesamiento y modelado de datos de texto. En esta ocasión, nos centraremos en un caso de aplicación que ya hemos estado trabajando: el análisis de discursos presidenciales.
Como venimos viendo, los discursos presidenciales son una fuente rica y diversa de información, que nos ofrece una ventana única hacia las políticas, prioridades y la retórica de los líderes políticos. En esta clase, aprovecharemos esta fuente de datos tal como está dispuesta, para profundizar en técnicas de programación que nos permiten su recolección y análisis
Nos centraremos en 2 procesos fundamentales:
Extracción de datos: sumaremos nuevas habilidades para recopilar discursos presidenciales de diversas webs utilizando técnicas avanzadas de escrapeo de datos.
Procesamiento de datos: daremos un paso más allá al explorar la lematización, una técnica esencial que simplifica y normaliza el texto, permitiéndonos agilizar el análisis.
Estas técnicas no solo complementan las herramientas de Procesamiento de Lenguaje Natural (NLP), sino que también tienen una amplia aplicabilidad en diversos contextos más allá de los discursos presidenciales. Desde la recolección de opiniones en redes sociales, hasta la evaluación de comentarios de clientes en plataformas de ecomerce, las técnicas que veremos en esta clase son utiles y convenientes1 para el análisis de texto en numerosos escenarios. Su utilidad se extiende a campos como la investigación académica, el análisis de la opinión pública y la toma de decisiones políticas y/o empresariales, proporcionando así una herramienta versátil y poderosa para comprender y actuar sobre los datos de texto no estructurado en el mundo real.
En la clase anterior, exploramos las primeras técnicas de Procesamiento de Lenguaje Natural (NLP) relacionadas con la lectura, tokenización, análisis y visualización de documentos de texto. En esta ocasión, nuestro objetivo será 1) extraer discursos presidenciales directamente de la web, 2) estructurarlos como una base de datos, 3) etiquetarlos y modelarlos usando udpipe.
La fuente de nuestros datos será el sitio oificial de la Casa Rosada, específicamente en la sección discursos:
El scraping, web scraping o raspado de datos, es una técnica empleada a través de código que nos permite extraer información de páginas web de forma automatizada. Si bien es ampliamente utilizada en el mundo de los datos, cabrá destacar que su aplicación genera algunos debates, especialmente en lo referente a su legalidad y ética.
Por un lado, el web scraping puede ser una herramienta poderosa para recopilar datos no estructurados de manera sistemática y construir nuestras propias bases, pero por otro lado, su uso inadecuado puede infringir los derechos de propiedad intelectual de los sitios web y ser utilizado para fines no éticos, como el envío de spam, el trolleo digital o la ingeniería social.
Para extraer datos de una página web de manera automatizada, es imprescindible comprender la estructura del HTML de esa página. El HTML, o Lenguaje de Marcado de Hipertexto, es el estándar utilizado para crear páginas web, organizando su contenido en elementos tales como etiquetas, atributos y texto.
Al familiarizarnos con esta estructura, podremos identificar y seleccionar de manera precisa los elementos específicos que desean extraer durante el proceso de scraping, que consiste en la extracción automatizada de datos de páginas web. Por consiguiente, el conocimiento general de HTML es clave para llevar a cabo el scraping de manera efectiva, ya que facilita la navegación y la extracción de datos de manera precisa y eficiente de las páginas web.
Veamos una estructura html simple:
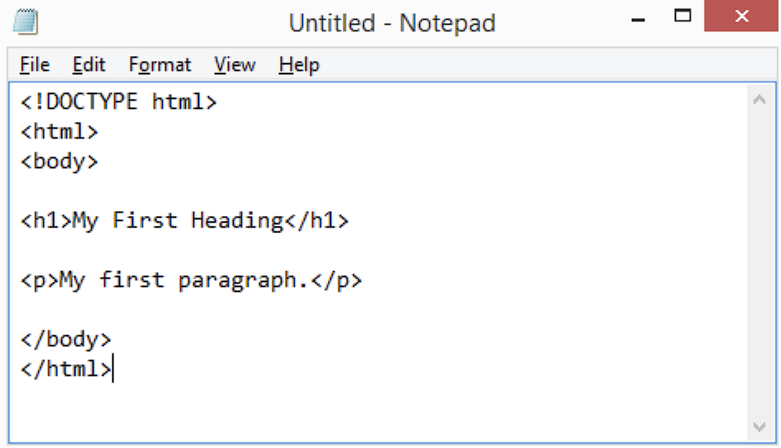
Como se puede observar, la página web presenta una estructura que incluye un encabezado <h1> (el más grande) seguido de un párrafo <p>. Estos elementos, como el <h1> y <p>, se denominan etiquetas o tags en HTML. Las etiquetas son elementos fundamentales del lenguaje HTML y se utilizan para definir la estructura y el contenido de una página web. Cada etiqueta tiene un propósito específico y define cómo se presenta o se organiza cierto contenido en la página. Por ejemplo, el <h1> se utiliza típicamente para encabezados principales, mientras que el <p> se utiliza para párrafos de texto.
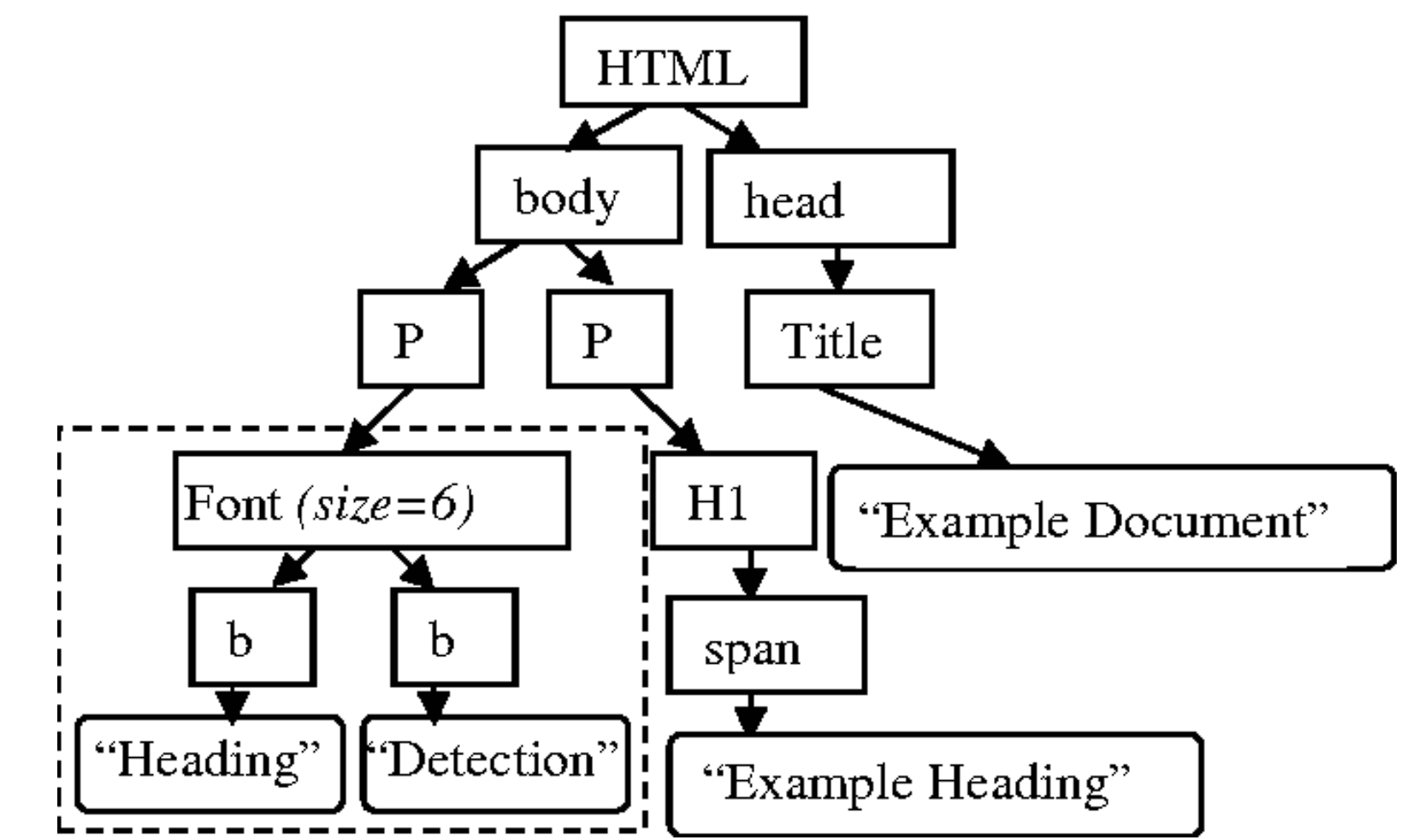
El lenguaje HTML se estructura de forma jerárquica, lo que significa que las etiquetas se organizan una dentro de otra, o se acompañan de texto si no hay más subniveles. Las etiquetas permiten identificar claramente dónde comienza y termina cada nivel de la estructura.
Además, los elementos HTML pueden tener atributos. Por ejemplo, la etiqueta <a> se usa para crear hipervínculos a otras páginas web, y se referencia mediante el atributo href, que indica la dirección URL a la que el hipervínculo lleva. Los atributos proporcionan información adicional sobre cómo debe comportarse o presentarse un elemento HTML
Tidyverse cuenta con una serie de funciones dentro de su “universo” que facilitan la escritura de código para extraer información web y se localizan dentro de los dominios de la librería rvest.
Vamos conocer en este apartado cómo operan sus principales funciones en la práctica con medios idgitales y luego replicaremos la lógica con nuestro objeto principal, que es la web de la casa rosada.
Definición la URL de la página web a scrapear: definimos la URL de la página web que que queremos analizar.
# Definir la URL de la página web a scrapear
url <- "https://www.infobae.com/sociedad/policiales/2024/05/11/una-empleada-estatal-de-mendoza-robo-hasta-26-millones-de-pesos-del-ministerio-de-produccion-como-fue-el-desvio-de-fondos/"Lectura del HTML de la página: Con la función read_html(url), leemos el código HTML de la página web especificada (infobae) por la URL y lo almacenamos en la variable, en este caso un objeto llamado html. Esto nos proporciona una representación del contenido de la página web en formato HTML que podemos analizar y extraer información.
# Leel el HTML de la página web
html <- read_html(url)
html{html_document}
<html lang="es" style="scroll-behavior:smooth">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body class="nd-body">\n<noscript><img src="https://sb.scorecardresearch. ...Obtención de los hijos directos del nodo raíz (etiqueta HTML): El nodo raíz es el elemento principal del documento HTML, y los “hijos directos” son los elementos HTML que están inmediatamente dentro del nodo raíz.
En este paso, estamaremos extrayendo hijos directos (head y body) y almacenándolos en la variable children.
# Obtener los hijos directos del nodo raíz (etiqueta HTML)
children <- html %>%
html_children()
children{xml_nodeset (2)}
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body class="nd-body">\n<noscript><img src="https://sb.scorecardresearch. ...Extracción del texto de todos los nodos p (párrafos): Aquí utilizamos el selector css"p" para seleccionar todos los elementos HTML <p> (párrafos) en la página web. Luego, con la función html_text(), extraemos el texto contenido en estos párrafos y lo almacenamos en la variable parrafos. Esto nos permite capturar el contenido de texto de la página, como noticias, descripciones, etc. Es en general una de las funciones que más usaremos.
# Obtener el texto de todos los nodos p (párrafos)
parrafos <- html %>%
html_nodes("p") %>%
html_text()
#parrafos
parrafos_df <- as.data.frame(parrafos) #psamos el texto a un df rapido
parrafos_df parrafos
1 21 Jun, 2024
2 Nuevo
3 Una empleada estatal de la provincia de Mendoza que se desempeñaba como técnica administrativa fue despedida en la última semana luego de que se descubriera que había robado hasta 26 millones de pesos del Ministerio de Producción. Lo hizo adulterando la información de un programa de subsidios destinado a empresas.
4 La mujer -a quien le comunicaron su despido el pasado martes en presencia de un escribano público- está identificada como Valentina Cáceres. Tiene 20 años y había ingresado a trabajar en la administración del plan “Enlazados” a comienzos de 2023. Fue a fines de ese mismo año, precisamente en diciembre, que comenzó a llevar adelante su fraude millonario. Este lo realizaba en complicidad con otras 31 personas, a las cuales les desviaba unos 200 mil pesos cada mes.
5 La operatoria la lograba a partir de la modificación de datos de los beneficiarios del mencionado subsidio, que fue creado con el objetivo de impulsar la creación de empleo. A través de este, el Gobierno mendocino otorga una ayuda a las compañías que cumplan con ciertos requisitos con el pago del sueldo de sus empleados nuevos. La suma de dinero, que equivale a un salario mínimo, se les transfiere durante los primeros cuatro meses y es depositado directamente al trabajador.
6 Cáceres tenía acceso al listado de las empresas beneficiarias y a los datos de las nuevas personas incorporadas en cada una de ellas, quienes iban a recibir el complemento salarial en la fecha de pago correspondiente. Así fue como todos los meses la mujer lograba entrar al sistema y agregar los nombres y CBU de sus cómplices, haciendo que estos percibieran la plata del subsidio.
7 No lo hacía en cualquier momento del mes: los añadía entre la fecha de control de planillas y el día de pago. Una vez que se depositaban los sueldos, la empleada estatal volvía a entrar al documento y borraba los nombres de las 31 personas que había agregado de manera fraudulenta y aleatoria a las empresas que participaban del plan.
8 Su modus operandi funcionó durante varios meses. Sin embargo, fue descubierto en las últimas semanas, cuando la joven quiso dar un paso más: sumó a la lista una compañía apócrifa, o fantasma, y quiso agrupar en ella a todos sus cómplices.
9 Sin embargo, este cambio no pasó desapercibido. En el marco de la crisis económica, llamó la atención que una empresa contratara a tantos nuevos empleados. En consecuencia, se procedió a una revisación de los datos y de quiénes habían sido las últimas personas que habían ingresado a la planilla.
10 Entonces figuró el nombre de Cáceres, cuyos ingresos al listado de datos se comprobaron posteriormente cuando se examinó su computadora y se vio el documento en su historial.
11 “Siempre hacía el movimiento en los días previos al proceso de generación de las órdenes de pago de los subsidios. Esto ocultó su operatoria frente a los controles internos de rutina que se realizaron, pero no advirtió que todos los datos y usuarios que operan el sistema son respaldados en servidores internos, sobre los que se realizan otros controles adicionales de integridad de la información y procesos”, informaron fuentes del gobierno mendocino a Infobae.
12 Y agregaron sobre el descubrimiento: “Así fue detectada la irregularidad, porque existía una huella digital de toda la operatoria fraudulenta. Ante estos hechos, la técnica administrativa fue desvinculada del programa y se continúa con la auditoría interna”.
13 Los 31 beneficiarios cobraron en forma irregular aproximadamente $ 200 mil pesos mensuales, alcanzando unos $26 millones al 30 de abril de 2024. Toda esta información fue expuesta en la presentación realizada en la Fiscalía de Delitos Económicos.
14 NuevoRecopilación de los atributos de los nodos a (hipervínculos): De manera similar al paso anterior, usamos el selector CSS "a" para seleccionar todos los elementos HTML <a> (hipervínculos) en la página web. Luego, con la función html_attrs(), extraemos los atributos de estos hipervínculos y los almacenamos en la variable atributos. Esto puede incluir información como URLs de enlaces, títulos, etc.
# Obtener los atributos de los nodos a (hipervínculos)
links_web <- html %>%
html_nodes("a") %>%
html_attrs()
#links_webPuesto que es muy probable que en la práctica operemos con más de un texto, vamos ahora a escrapear una lista de links y a visualizar las frecuencias de los contenidos obtenidos.
Establecemos la lista de enlaces que queremos analizar, en este caso nos interesa observar la cobertura de un mismo evento por parte de 3 medios digitales diferentes prestando atención a las 10 palabras más mencionadas en cada caso.
# Lista de enlaces
lista_enlaces <- c(
"https://www.infobae.com/economia/2024/05/15/que-creen-que-la-inflacion-baja-sola-y-otras-frases-de-javier-milei-ante-empresarios-en-cicyp/",
"https://www.ambito.com/economia/javier-milei-el-atraso-cambiario-es-una-hipotesis-equivocada-n5998846",
"https://www.pagina12.com.ar/736249-javier-milei-el-debate-de-la-ley-bases-y-el-pacto-de-mayo"
# se puende cambiar, o agregar mas
)Acto seguido, utilizando la función map2, aplicaremos una serie de operaciones a cada elemento de la lista lista_enlaces, que contiene las direcciones URL de las páginas web que queremos analizar.
Para cada URL en la lista, nuestro código primero lee el HTML de la página web correspondiente utilizando read_html(). Luego, utiliza html_nodes("p") para seleccionar todos los nodos <p> (párrafos) del HTML y html_text() para extraer el texto contenido en esos párrafos. Los resultados se almacenan en una lista llamada resultados, donde cada elemento contiene los párrafos extraídos de una página web específica.
# Obtener párrafos de cada enlace
notas_anidadas <- map(lista_enlaces, ~ read_html(.x) %>%
html_nodes("p") %>%
html_text())Dado que notas_anidadas se encuentra en una lista anidada, la transformaremos en un dataset tubular llamado notas que optimizará el análisis.
Lo estructuraremos innicialmente con tres columnas: link, que contiene las URLs de las páginas web; texto, con los textos de los párrafos extraídos; y nombre_medio, que extrae el nombre del dominio de cada URL.
Como en este caso el link no nos aporta mas valor, sobre el final del proceso lo descartaremos.
# Crear el dataframe
notas <- tibble(
link = rep(lista_enlaces, lengths(notas_anidadas)),
texto = unlist(notas_anidadas),
nombre_medio = str_extract(link, "(?<=www\\.)[^.]+") # Extraer el nombre del dominio
)
# Imprimir el dataframe
notas_final <- notas %>%
select(nombre_medio, texto)Pre procesamos con los pasos que ya conocemos:
# Tokenizamos el texto y convertir a minúsculas
notas_tokenizado <- notas_final %>%
unnest_tokens(word, texto) %>%
mutate(word = tolower(word))
#cargamos los conectores que vamos a filtrar
stopwords_es <- stopwords("es")
# Convertimos stopwords_es en un tbl_df
stopwords_es_tbl <- tibble(word = stopwords_es) #hacemos esto por formato
# Filtramos stopwords
notas_filtradas <- notas_tokenizado %>%
anti_join(stopwords_es_tbl)
# Contamos la frecuencia de palabras
frecuencia_palabras <- notas_filtradas %>%
count(nombre_medio, word, sort = TRUE) %>%
group_by(nombre_medio) %>%
arrange(desc(n)) %>%
slice_head(n = 10)ggplot(frecuencia_palabras, aes(x = reorder(word, n), y = n)) +
geom_bar(stat = "identity") +
facet_wrap(~ nombre_medio, scales = "free") +
coord_flip() +
labs(x = "Palabra", y = "Frecuencia", title = "Frecuencia de palabras por medio") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))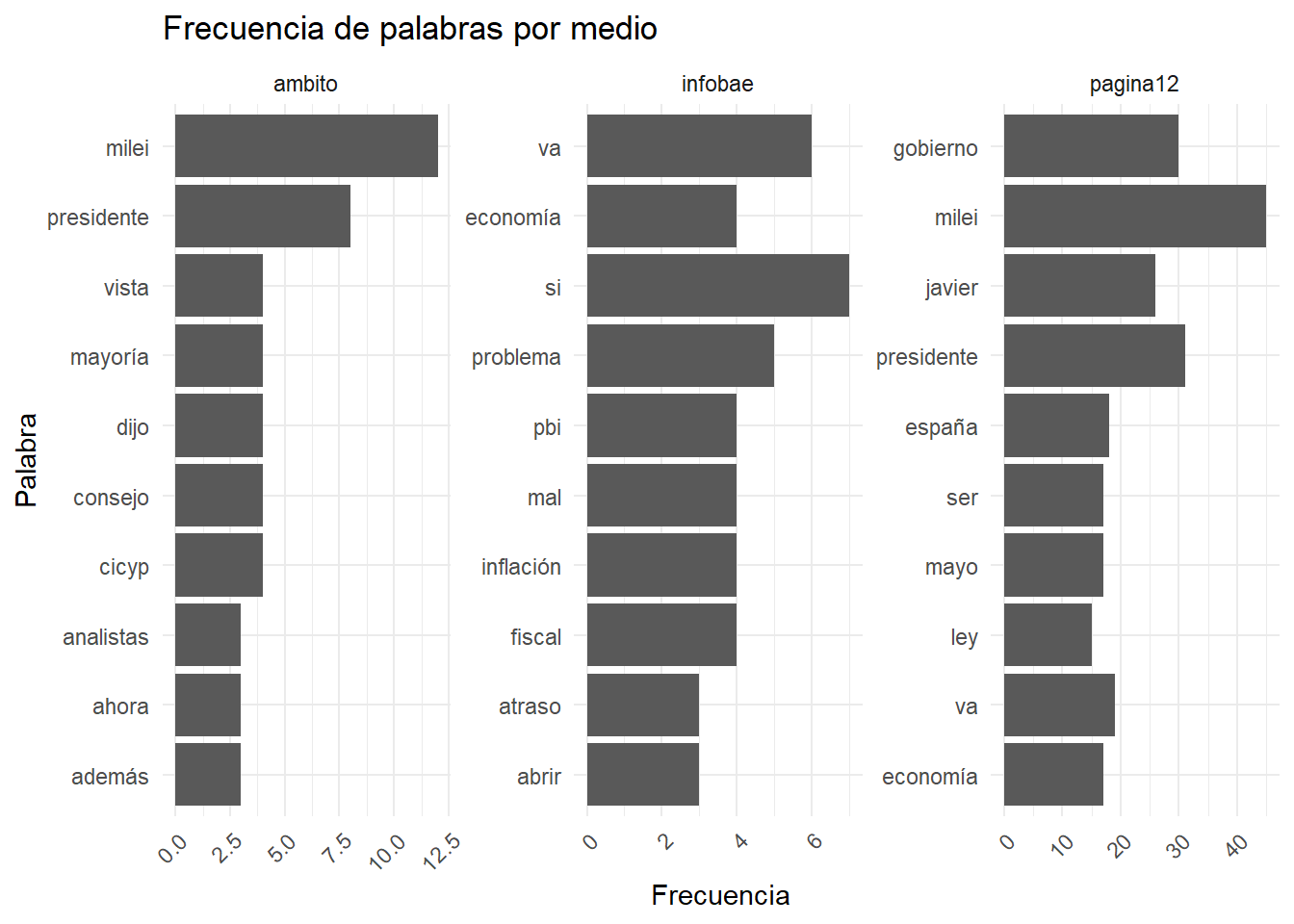
Nota: no termino de entender por qué el ultimo facet no se ordena 😭 para lo que viene no vamos a usar ggplot…

Aquí crearemos un proceso (una función custom) que de manera automática va a conectarse a la web de la Casa Rosada y extraerá los links de los discursos del Presidente. Una vez que los enlaces fueron identificados, nuestro proceso extaerá discurso por discurso el contenido textual.

Finalmente lo limpiaremos, almacenaremos y estructuraremos como un corpus de textos con un título, una fecha y un texto principal.
glue)Recordemos que en R y otros lenguajes de programación, las funciones son bloques de código que realizan una tarea específica. Pueden aceptar cero o más argumentos como entrada, realizar cálculos, manipular datos y producir un resultado. Las funciones son una parte fundamental de la programación y una herramienta poderosa para escribir código modular y reutilizable.
Antes de pasar a la creación de nuestras propias funciones para la recopilación sistemática de texto ,vamos a repasar la lógica de una función custom y conocer glue.
glue es una función super útil de tidyverse que facilita la creación de cadenas de texto dinámicas, permitiendo la interpolación de variables directamente en el texto. En lugar de concatenar manualmente cadenas de texto y variables usando el operador de concatenación (paste() o paste0()), glue simplifica este proceso al permitirnos incluir directamente variables dentro del texto utilizando llaves {}. Esto hace que el código sea más claro, conciso y fácil de mantener.
En el ejemplo que sigue, creamos la función saludar utiliza glue para generar un mensaje de saludo personalizado, donde el nombre de la persona a saludar se inserta dinámicamente en el mensaje.
# Definimos la función para saludar
saludar <- function(nombre) {
mensaje <- glue("¡Hola, {nombre}! ¿Cómo estás?")
return(mensaje)
}
# Utilizamos la función para saludar a una persona
nombre <- "Máquina"
mensaje_saludo <- saludar(nombre)
# Imprimir el mensaje de saludo
mensaje_saludo¡Hola, Máquina! ¿Cómo estás?Con esta idea en la cabeza, vamos a crear ahora dos funciones principales para extraer los textos de los discursos presidenciales.
Comenzamos creando get_new_links , una función que codeamos para obtener nuevos enlaces de la pagina de discursos de la rosada. El proceso comienza estableciendo el enlace base proporcionado como punto de referencia. Luego, utiliza la función read_html de rvest para leer el HTML del enlace y seleccionar todos los nodos de enlaces <a> utilizando html_nodes.
Seguidamente, la función crea un dataframe con dos columnas: link, que contiene los enlaces extraídos, y titulo, que contiene los textos asociados a los enlaces. Posteriormente, filtra los enlaces para seleccionar solo aquellos que son relevantes para discursos utilizando str_detect, y elimina cualquier enlace duplicado. Si ocurre algún error durante el proceso, la función maneja el error y muestra un mensaje personalizado utilizando la función glue, indicando el enlace donde ocurrió el error.
La estructura tryCatch permite ejecutar el código dentro del bloque {} y manejar cualquier error que ocurra durante la ejecución. Si ocurre un error, se mostrará un mensaje personalizado indicando el problema.
# codigo para obtener nuevos enlaces de una página
get_new_links <- function(link){
tryCatch({
base <- link # Establece el enlace base
nodes <- read_html(link) %>% rvest::html_nodes("a") # Obtiene nodos de enlaces
df <- tibble(link = html_attr(nodes, "href"), titulo = html_text(nodes)) %>% # Crea data frame con enlaces y títulos
filter(str_detect(link, "informacion/discursos/\\d"), !is.na(link)) %>% # Filtra enlaces relevantes
mutate(link = gsub("#.*", "", link), link = xml2::url_absolute(link, base = base)) %>% # Limpia enlaces
distinct(link, .keep_all = TRUE)# Elimina duplicados
df
}, error = function(err) {
glue::glue("Error en el enlace: {link}") # Maneja errores y muestra eventuales mensaje de error
})
}Vamos a crear una segunda función denominada get_text, en este caso el código nos va a permitir extraer los textos de cada link que le demos.
# nuestra función para extraer texto de de manera sistemática
get_text <- function(link){
tryCatch({
pagina <- read_html(link)# Lee el HTML de la página
texto <- pagina %>% html_nodes('.jm-allpage-in') %>% html_text()# Extrae texto de la clase .jm-allpage-in
titulo <- pagina %>% html_nodes('strong') %>% html_text() # Extrae títulos usando etiqueta <strong>
df <- tibble(texto = texto, titulo = titulo) # Crea un data frame con texto y títulos
Sys.sleep(1) # Espera un segundo para evitar sobrecargar el servidor
df
}, error = function(err) {
glue::glue("Error en el enlace: {link}") # Maneja errores y muetra un mensaje de error
})
}Con get_text podremos extraer los textos de cada enlace proporcionado de manera sistemática. Utilizando la función read_html , leeremos el HTML de la página web y seleccionaremos los nodos <a> (enlaces). Luego, crearemos un dataframe con dos columnas: texto, que contiene los textos extraídos, y titulo, que guarda el texto asociado a cada enlace. Filtraremos los enlaces para seleccionar solo aquellos relevantes, identificados por la presencia de discursos, y limpiaremos los enlaces para eliminar partes no deseadas. En caso de error, se mostrara un mensaje personalizado con la URL del enlace problemático.
Con nuestras funciones definidas vamos a poner en marcha el proceso de extracción de textos.
En primer lugar, vamos a definir el enlace principal en la variable, es decir el link al que se debe conectar nuestro escrapeador para hacer su tarea.
Luego crearemos un objeto llamado paginas que contiene el enlace principal.
paginas <- 'https://www.casarosada.gob.ar/informacion/discursos'Porgamos en acción la función custom de escrapeo get_new_links, que va a descargar todos los enlaces del body de la web de discursos.
La función map se emplea para aplicar una función a cada elemento de una lista o vector y devuelve una lista con los resultados de esa función aplicada a cada elemento.
paginas_df <- tibble(paginas=paginas) %>%
mutate(new_links= map(paginas, get_new_links)) %>%
unnest(cols = c(new_links))Vamos a obtener una tabla de 40 enlaces que se corresponden con los últimos discursos presidenciales publicados. Utilicemos ahora la función get_text para descargar los discursos de cada link.
corpus <- paginas_df %>%
#head(10) %>%
mutate(cuerpo = map(link, get_text)) %>%
unnest() %>%
distinct()En una primera limpieza de los datos para simplificar los procesos de análisis, vamos a extraer las fechas de los títulos de los textos utilizando expresiones regulares y crearemos una columna temporal con mutate. Luego, seleccionamos únicamente las columnas importantes: enlaces, las fechas y los textos, para mantener solo la información esencial. Seguidamente, eliminaremos las filas duplicadas en el corpus para asegurarnos de que cada entrada sea única.
Para finalizar utilizaremos nuestra columna de fecha para filtrar los discursos del ex Presidente Fernández.
Asi queda nuestro código:
# Limpiar y transformar datos
corpus_limpio <- corpus %>%
mutate(fecha = lubridate::dmy(str_extract(titulo, '\\d+ de [[:alpha:]]+ de \\d{4}'))) %>%
select(link, fecha, texto) %>%
distinct() %>%
filter(fecha>"2023-12-9")La columna de texto que analizaremos al momento se ve asi:
corpus_limpio %>%
select(texto) %>%
head(1)# A tibble: 1 × 1
texto
<chr>
1 "\r\n \r\n \r\n …Un horror.
Por eso vamos a terminar limpiar la columna texto utilizando str_replace_all() para reemplazar todos los saltos de línea y espacios en blanco múltiples por un solo espacio en blanco. Luego con str_squish() vamos eliminar cualquier espacio en blanco adicional al principio o al final del texto:
corpus_limpio <- corpus_limpio %>%
mutate(texto_limpio = str_replace_all(texto, "\\r\\n|\\s+", " ")) %>%
mutate(texto_limpio = str_squish(texto_limpio))
head(corpus_limpio)# A tibble: 6 × 4
link fecha texto texto_limpio
<chr> <date> <chr> <chr>
1 https://www.casarosada.gob.ar/informacion/discu… 2024-06-20 "\r\… "Palabras d…
2 https://www.casarosada.gob.ar/informacion/discu… 2024-06-15 "\r\… "Palabras d…
3 https://www.casarosada.gob.ar/informacion/discu… 2024-06-12 "\r\… "Discurso d…
4 https://www.casarosada.gob.ar/informacion/discu… 2024-06-12 "\r\… "Palabras d…
5 https://www.casarosada.gob.ar/informacion/discu… 2024-06-06 "\r\… "Palabras d…
6 https://www.casarosada.gob.ar/informacion/discu… 2024-06-05 "\r\… "Palabras d…Hecho!
Para concluir el escrapeo nos guardamos la data en csv, dentro de nuestro espacio de trabajo.
# Guardar datos en un archivo CSV
corpus_limpio %>% write_csv("corpus_limpio.csv")Análisis de frecuencias preliminar
corpus_tokenizado = corpus_limpio %>%
unnest_tokens(output = word,
input = texto)Descartamos conectores, y términos que no aportan valor sustantivo al analisis.
stop_es<- stopwords("spanish") #armamos un vector con las stopwords en esp
# palabras_inutiles <- c("digamos", "decir", "si", "digo", "entonces")
discurso_tidy<-corpus_tokenizado%>%
filter(!(word %in% stop_es)) %>%
# filter(!(word %in% palabras_inutiles)) %>%
filter(str_detect(word, "^[a-zA-z]|^#|^@"))Graficamos por fecha la palabra inflación, un tema central en la agenda del Gobierno Nacional.
discurso_tidy %>%
group_by(word, fecha) %>%
arrange(fecha) %>%
count() %>%
filter(word=="inflación") %>% #selecciono la palabra inflación
ggplot() +
aes(x = fecha, weight = n) +
geom_bar(fill = "#4682B4") +
labs(
x = "Fecha",
y = "Catidad de menciones",
title = "Menciones de la palabra inflación en los discursos del Presidente Javier Milei",
subtitle = "Analisis NLP de discursos presidenciales 2023 - 2024",
caption = "Fuente: elaboración propia en base a datos recopilados de la web de Casa Rosada"
) +
theme_minimal()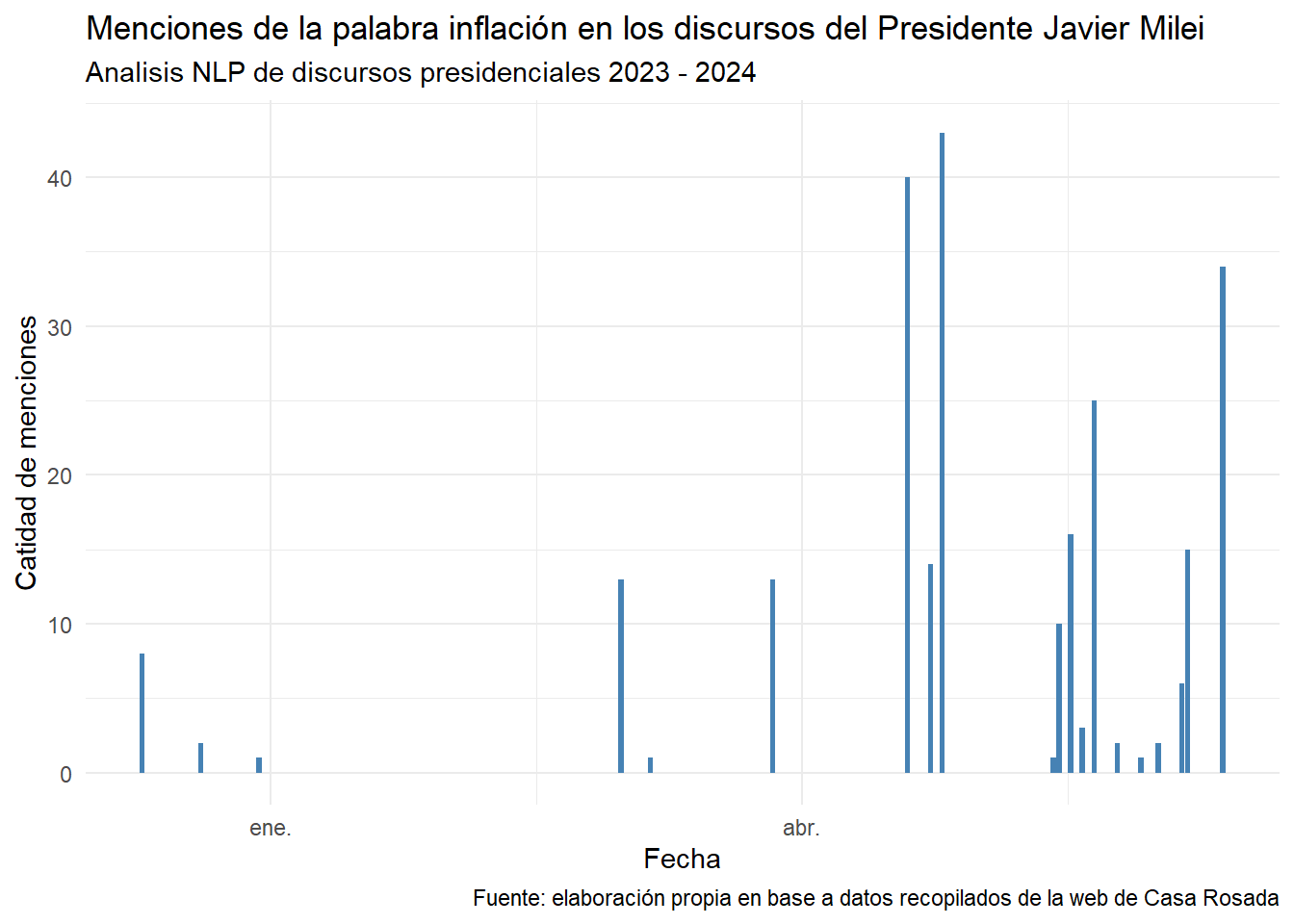
Principales frecuencias:
palabras_inutiles<- c("años", "año", "además", "aplausos", "decir",
"entonces", "si", "va", "ustedes"
# ,digamos
)
discurso_tidy %>%
group_by(word) %>%
filter(!(word %in% palabras_inutiles)) %>%
count() %>%
arrange(n) %>% # Ordenar de menor a mayor
tail(20) %>% # Seleccionar las 20 palabras con mayor frecuencia
ggplot() +
aes(x = reorder(word, n), y = n) + # Reordenar las palabras según su frecuencia
geom_col(fill = "#82aaab", alpha=0.8) +
theme_minimal() +
labs(title = "Palabras más frecuentes en los discursos de Milei",
subtitle = "Analisis NLP de discursos presidenciales 2023 - 2024",
caption = "Fuente: elaboración propia en base a datos recopilados de la web de Casa Rosada",
x = "Palabra",
y = "Frecuencia")+
coord_flip()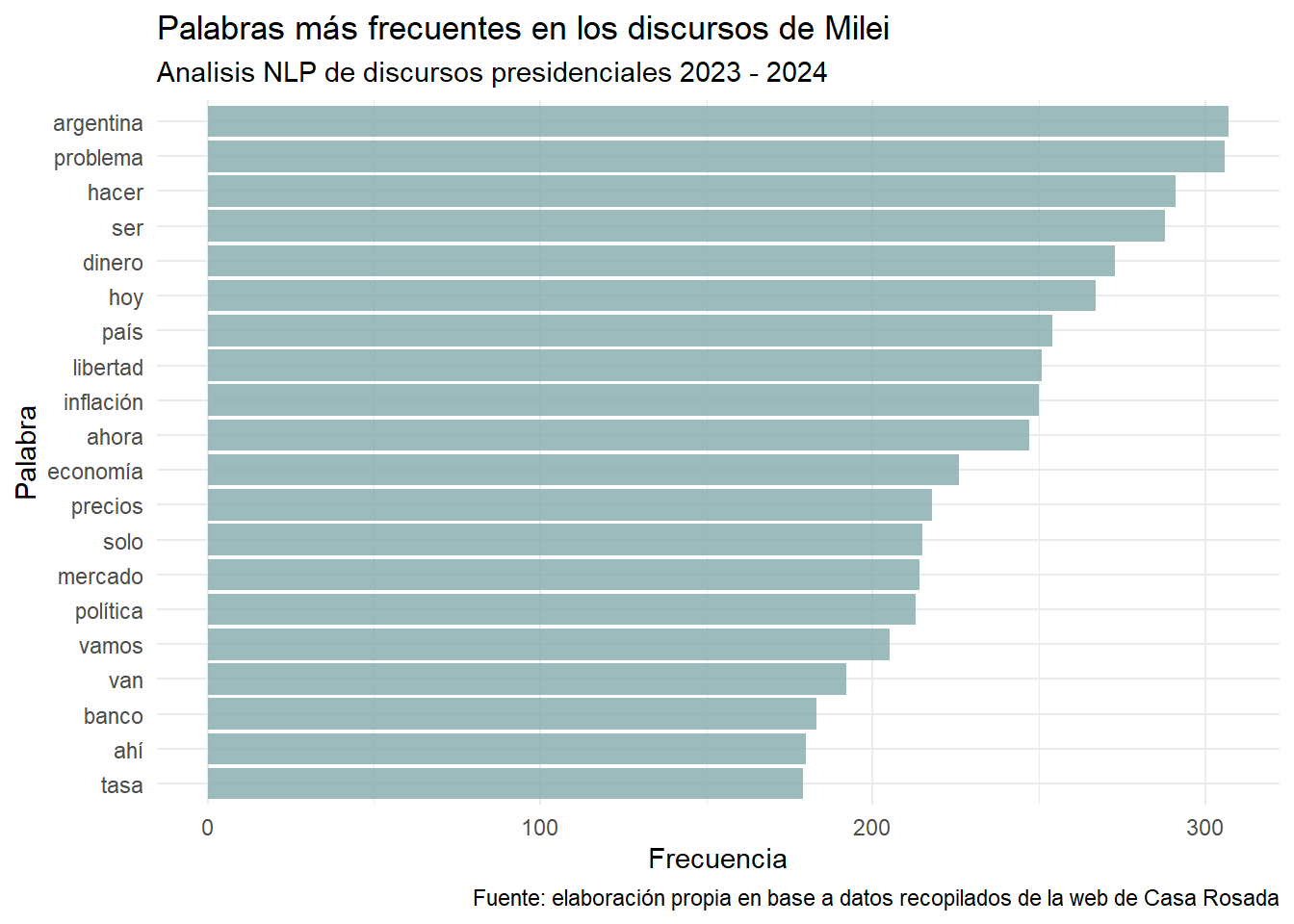
El etiquetado de datos en NLP es un factor clave para varias tareas, como el análisis gramatical, la extracción de información, la detección de entidades nombradas, el análisis de sentimientos y muchas otras aplicaciones. Proporciona la base para comprender la estructura y el significado del texto, lo que permite a los sistemas de NLP realizar tareas avanzadas como la generación de resúmenes, la traducción automática, la respuesta a preguntas y la clasificación de documentos, entre otras.
UDPipe es una biblioteca nos provee un conjunto de herramientas de procesamiento de lenguaje natural (PLN) orientadas al análisis de texto. Uno de los elementos clave de UDPipe son los modelos de lenguaje pre-entrenados. Estos modelos son conjuntos de datos estadísticos y parámetros que han sido entrenados con grandes cantidades de texto anotado en varios idiomas. Los modelos contienen información sobre cómo se estructuran y se relacionan las palabras en un idioma específico, lo que permite a UDPipe realizar tareas como tokenización (división de texto en unidades léxicas), etiquetado gramatical (asignación de categorías gramaticales a palabras), lematización (reducción de palabras a sus formas base) y análisis de dependencias (identificación de las relaciones sintácticas entre palabras).
Utilizaremos los modelos y funciones de udpipe para etiquetar y explorar los discursos presidenciales de Milei,
Para comentar a etiquetar nuestros datos, descarguemos el modelo con el que vamos a interpretar el corpus de discursos
ud_model <- udpipe_download_model(language = "spanish")
ud_model <- udpipe_load_model(ud_model$file_model)
corpus_discursos<-corpus_limpio A continuación realizaremos el etiquetado morfosintácticode los discursos.
Primero, llamaremos al modelo previamente entrenado (almacenado en ud_model). Luego, aplicaremos este modelo al corpus de texto (almacenado en corpus_discursos$texto) utilizando la función udpipe_annotate, generando un data.frame llamado corpus_etiquetado que contiene información detallada sobre cada token en el texto, incluyendo su lema, parte del habla, y otras etiquetas morfosintácticas.
corpus_etiquetado <- udpipe_annotate(ud_model, x = corpus_discursos$texto, doc_id = corpus_discursos$link)
corpus_etiquetado <- as.data.frame(corpus_etiquetado)
head(corpus_etiquetado) doc_id
1 https://www.casarosada.gob.ar/informacion/discursos/50548-palabras-del-presidente-de-la-nacion-javier-milei-en-el-acto-del-dia-de-la-bandera-en-la-ciudad-de-rosario
2 https://www.casarosada.gob.ar/informacion/discursos/50548-palabras-del-presidente-de-la-nacion-javier-milei-en-el-acto-del-dia-de-la-bandera-en-la-ciudad-de-rosario
3 https://www.casarosada.gob.ar/informacion/discursos/50548-palabras-del-presidente-de-la-nacion-javier-milei-en-el-acto-del-dia-de-la-bandera-en-la-ciudad-de-rosario
4 https://www.casarosada.gob.ar/informacion/discursos/50548-palabras-del-presidente-de-la-nacion-javier-milei-en-el-acto-del-dia-de-la-bandera-en-la-ciudad-de-rosario
5 https://www.casarosada.gob.ar/informacion/discursos/50548-palabras-del-presidente-de-la-nacion-javier-milei-en-el-acto-del-dia-de-la-bandera-en-la-ciudad-de-rosario
6 https://www.casarosada.gob.ar/informacion/discursos/50548-palabras-del-presidente-de-la-nacion-javier-milei-en-el-acto-del-dia-de-la-bandera-en-la-ciudad-de-rosario
paragraph_id sentence_id
1 1 1
2 1 1
3 1 1
4 1 1
5 1 1
6 1 1
sentence
1 Palabras del Presidente de la Nación, Javier Milei, en el acto del Día de la Bandera, en la Ciudad de Rosario Argentinos, hoy conmemoramos el paso a la inmortalidad de Manuel Belgrano, héroe de la Revolución de Mayo y padre de nuestra bandera Argentina.
2 Palabras del Presidente de la Nación, Javier Milei, en el acto del Día de la Bandera, en la Ciudad de Rosario Argentinos, hoy conmemoramos el paso a la inmortalidad de Manuel Belgrano, héroe de la Revolución de Mayo y padre de nuestra bandera Argentina.
3 Palabras del Presidente de la Nación, Javier Milei, en el acto del Día de la Bandera, en la Ciudad de Rosario Argentinos, hoy conmemoramos el paso a la inmortalidad de Manuel Belgrano, héroe de la Revolución de Mayo y padre de nuestra bandera Argentina.
4 Palabras del Presidente de la Nación, Javier Milei, en el acto del Día de la Bandera, en la Ciudad de Rosario Argentinos, hoy conmemoramos el paso a la inmortalidad de Manuel Belgrano, héroe de la Revolución de Mayo y padre de nuestra bandera Argentina.
5 Palabras del Presidente de la Nación, Javier Milei, en el acto del Día de la Bandera, en la Ciudad de Rosario Argentinos, hoy conmemoramos el paso a la inmortalidad de Manuel Belgrano, héroe de la Revolución de Mayo y padre de nuestra bandera Argentina.
6 Palabras del Presidente de la Nación, Javier Milei, en el acto del Día de la Bandera, en la Ciudad de Rosario Argentinos, hoy conmemoramos el paso a la inmortalidad de Manuel Belgrano, héroe de la Revolución de Mayo y padre de nuestra bandera Argentina.
token_id token lemma upos xpos
1 1 Palabras palabra NOUN <NA>
2 2-3 del <NA> <NA> <NA>
3 2 de de ADP <NA>
4 3 el el DET <NA>
5 4 Presidente presidente NOUN <NA>
6 5 de de ADP <NA>
feats head_token_id dep_rel deps
1 Gender=Fem|Number=Plur 0 root <NA>
2 <NA> <NA> <NA> <NA>
3 <NA> 4 case <NA>
4 Definite=Def|Gender=Masc|Number=Sing|PronType=Art 4 det <NA>
5 <NA> 1 nmod <NA>
6 <NA> 7 case <NA>
misc
1 SpacesBefore=\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\r\\n\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s\\s
2 <NA>
3 <NA>
4 <NA>
5 <NA>
6 <NA>Para finalizar la clase utilizaremos algunas funciones de udpipe para resumir datos de texto y explorar el corpus discursivo que escrapeamos.
Las estadísticas de frecuencia básica nos muestran qué tipos de palabras son más comunes en un texto o corpus. En la mayoría de los idiomas, los sustantivos y los verbos son los más frecuentes, ya que representan nombres de personas, lugares, acciones y estados. Estas categorías, conocidas como UPOS(Universal Parts of Speech), son cruciales para el análisis, ya que permiten comprender quién o qué realiza las acciones en el texto. Los adjetivos, que describen características de los sustantivos, y los nombres propios, que identifican entidades específicas, también son relevantes. Conocer la frecuencia de estos tipos de palabras ayuda en la comprensión del texto y en tareas analíticas como el análisis de sentimientos o la extracción de información.
Udpipe ademas de haber etiquetado las palabras con upos, nos provee de la función txt_freqpara calcular automáticamente las frecuencias de ésta y otras columnas. Veamos como funciona y visualicemos con lattice.
stats <- txt_freq(corpus_etiquetado$upos)
stats <- stats %>%
mutate(llave = case_when(
key == "NOUN" ~ "SUSTANTIVO",
key == "DET" ~ "DETERMINANTE",
key == "VERB" ~ "VERBO",
key == "ADP" ~ "ADPOSICIÓN",
key == "PUNCT" ~ "PUNTUACIÓN",
key == "PRON" ~ "PRONOMBRE",
key == "ADV" ~ "ADVERBIO",
key == "SCONJ" ~ "CONJUNCIÓN SUBORDINADA",
key == "ADJ" ~ "ADJETIVO",
key == "AUX" ~ "VERBO AUXILIAR",
key == "CCONJ" ~ "CONJUNCIÓN COORDINADA",
key == "PROPN" ~ "NOMBRE PROPIO",
key == "NUM" ~ "NÚMERO",
key == "SYM" ~ "SÍMBOLO",
key == "X" ~ "OTRO",
key == "INTJ" ~ "INTERJECCIÓN",
key == "PART" ~ "PARTÍCULA",
TRUE ~ NA_character_ # Por si acaso hay algún otro valor en key que no se haya considerado
))
stats$llave <- factor(stats$llave, levels = rev(stats$llave))
barchart(llave ~ freq, data = stats, col = "gold",
main = "Partes del discurso universales (UPOS)\n segun frecuencia de ocurrencia en Discursos Presidenciales de Javier Milei",
xlab = "Frecuencia")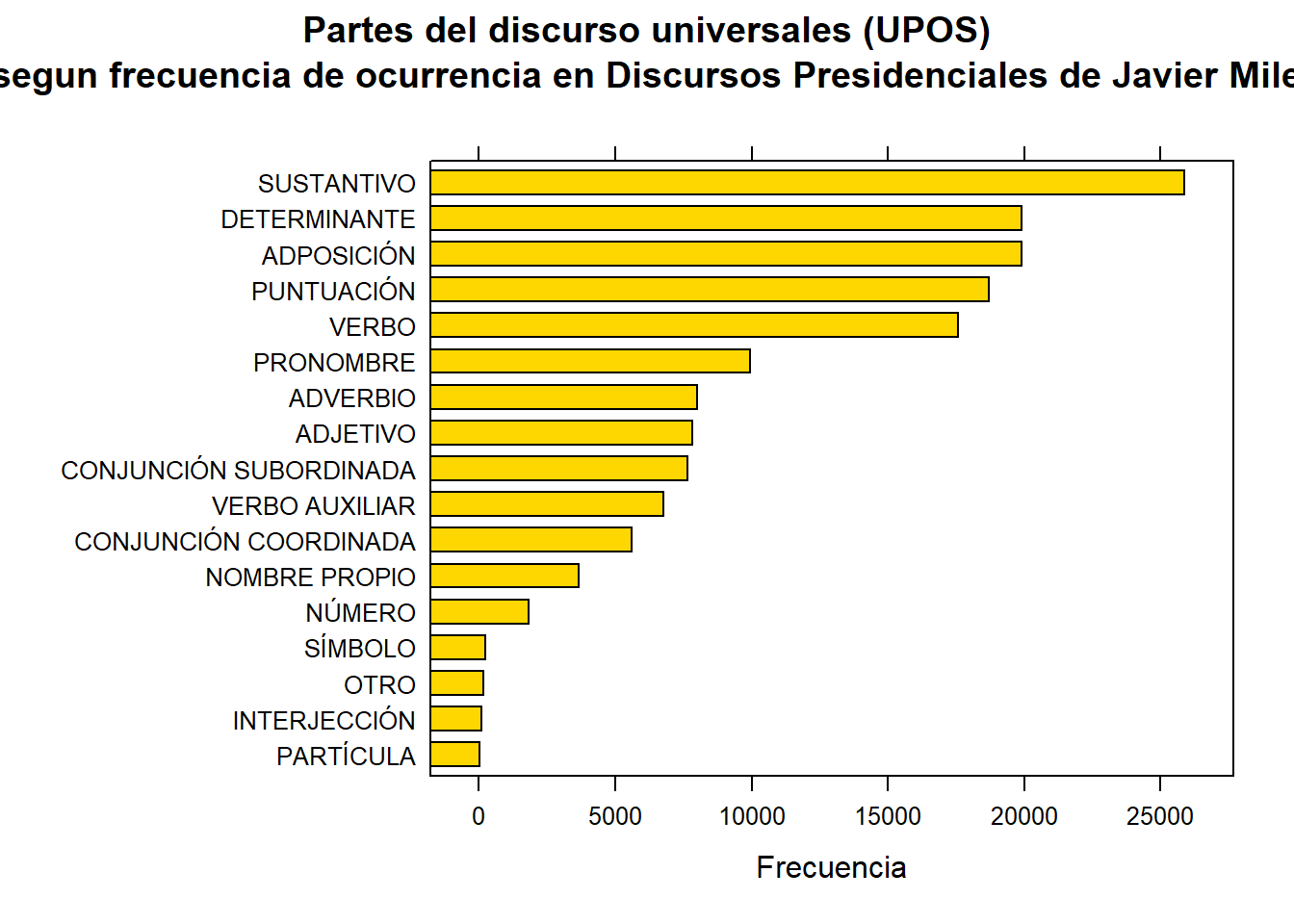
Las etiquetas de partes del discurso son muy útiles para seleccionar rápido las palabras que queremos graficar. No necesitamos usar el vector de palabras inútiles para esto; simplemente seleccionamos sustantivos, verbos o adjetivos, que son las partes más relevantes para un análisis de frecuencia básico.
sustantivos <- subset(corpus_etiquetado, upos %in% c("NOUN")) #otro tipo de filtro
sustantivos <- txt_freq(sustantivos$token)
sustantivos$key <- factor(sustantivos$key, levels = rev(sustantivos$key))
barchart(key ~ freq_pct,
data = head(sustantivos, 20), col = "purple",
main = "Sustantivos más frecuentes en
el discurso presidencial", xlab = "Frecuencias %")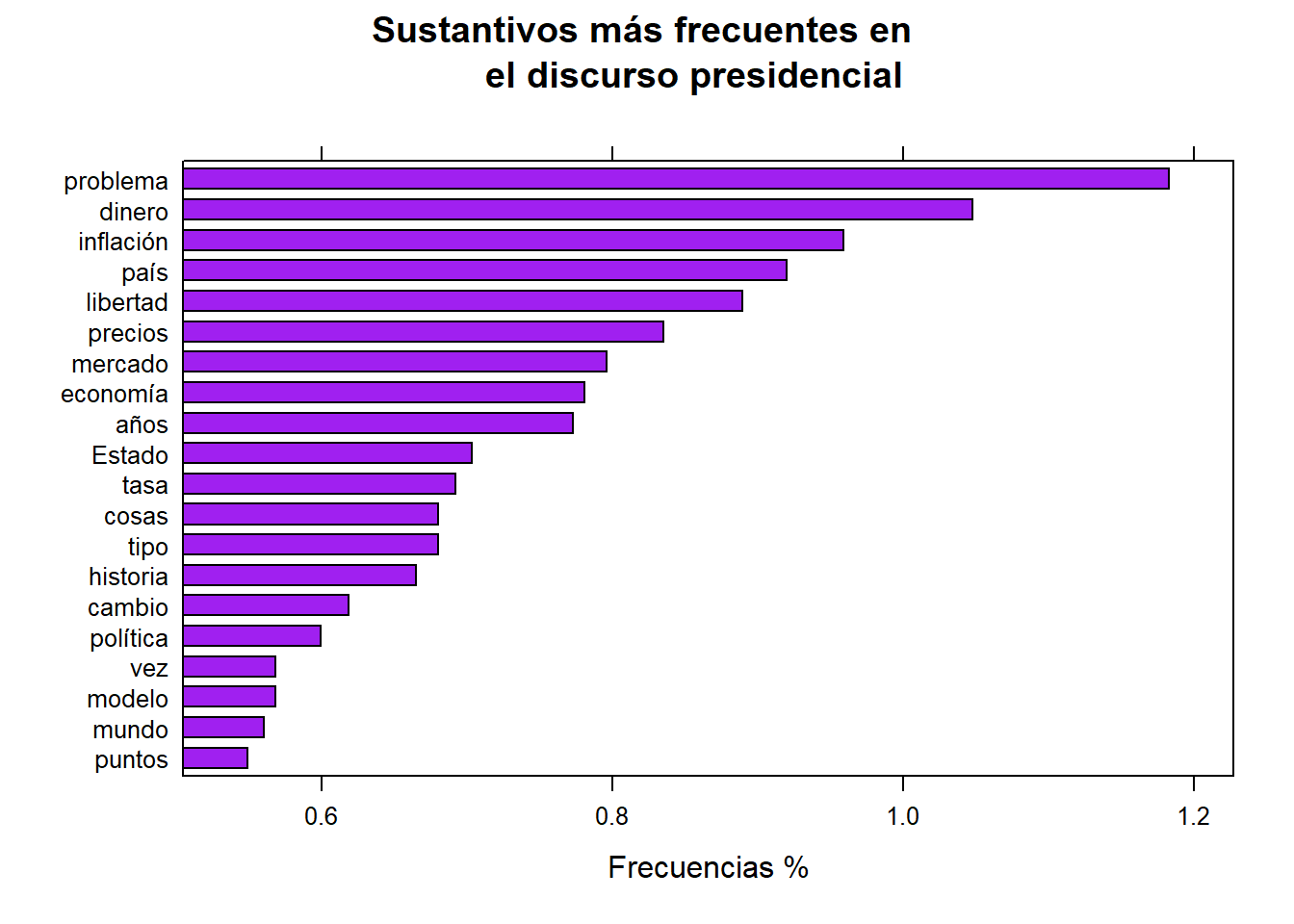
stats <- subset(corpus_etiquetado, upos %in% c("ADJ")) #otro tipo de filtro
stats <- txt_freq(stats$token)
stats$key <- factor(stats$key, levels = rev(stats$key))
barchart(key ~ freq_pct,
data = head(stats, 20), col = "tomato",
main = "Adjetivos más frecuentes en
el discurso presidencial", xlab = "Frecuencias %")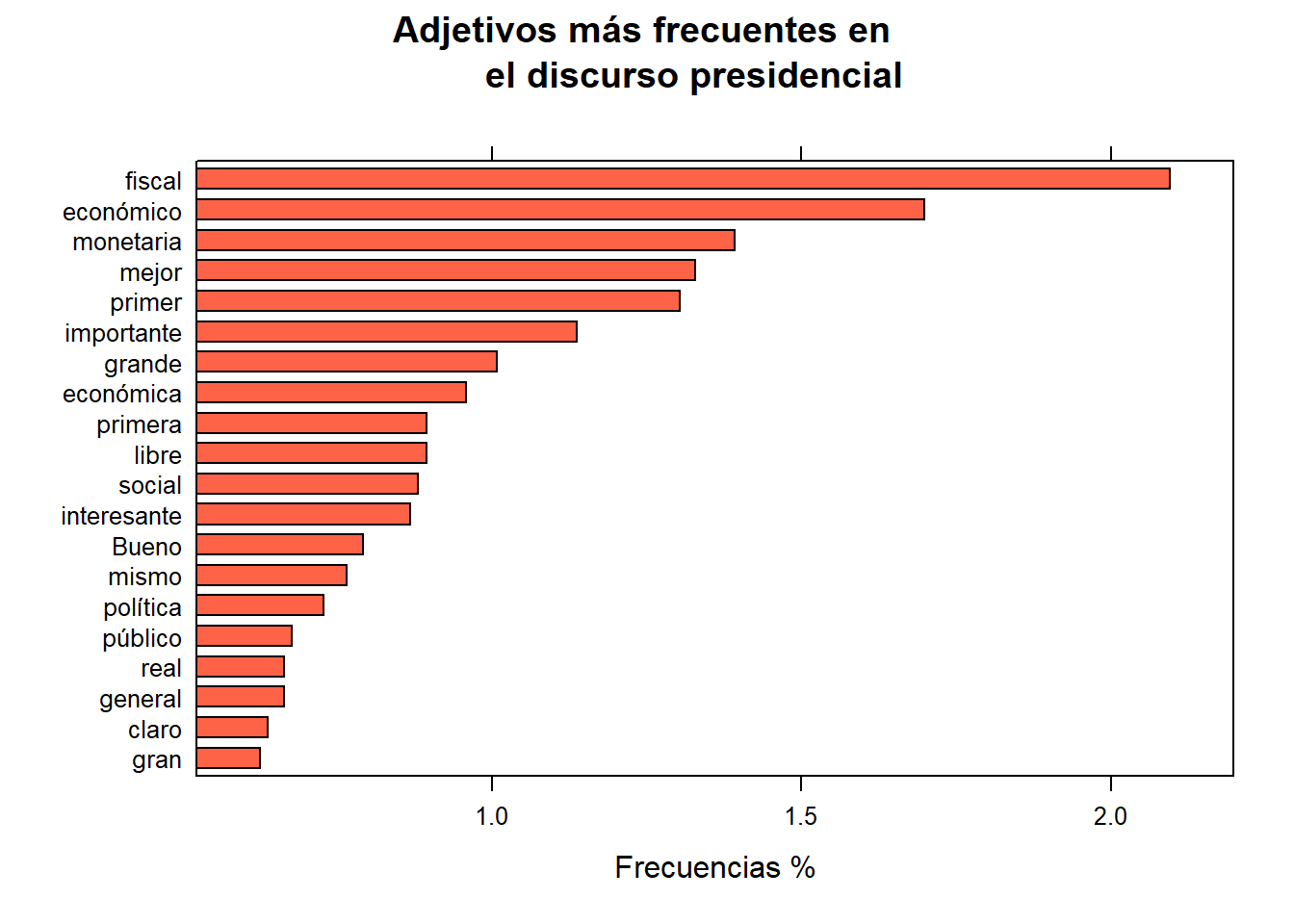
Las estadísticas de frecuencia de palabras son útiles, pero la mayoría de las veces, nos encontramos con palabras que solo tienen sentido en combinación con otras palabras. Por lo tanto, queremos encontrar palabras clave que tengan alta probabilidad de encontrarse juntas.
Para dar con las combinaciones udpipe nos ofrece 3 funciones que conoceremos a continuación dada su utilidad y aplicabilidad a la exploración del discurso presidencial.
RAKE es un método de extracción de palabras clave que identifica automáticamente las palabras o frases más relevantes en un texto. Utiliza un algoritmo que analiza la frecuencia de las palabras y la co-ocurrencia de términos para determinar la importancia de cada palabra clave.
rake <- keywords_rake(x = corpus_etiquetado, term = "lemma", group = "doc_id",
relevant = corpus_etiquetado$upos %in% c("NOUN", "ADJ"))
rake$key <- factor(rake$keyword, levels = rev(rake$keyword))
barchart(key ~ rake, data = head(subset(rake, freq > 3), 20), col = "#9ab6ce",
main = "Identificacion de conceptos
clave utilizando RAKE",
xlab = "Rake")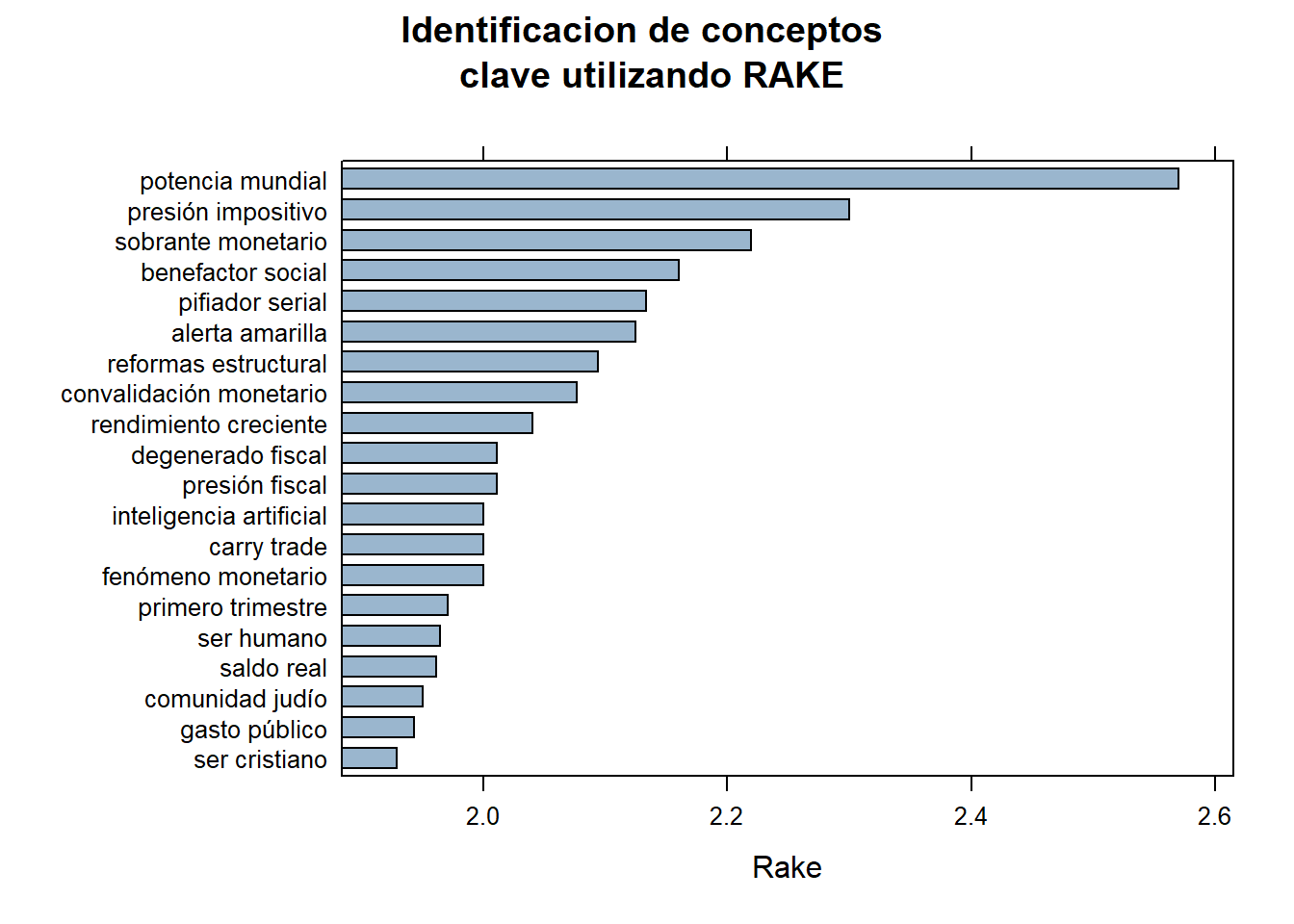
Este método utiliza la Información Mutua Puntual (PMI para lxs amigxs) para identificar las colocaciones más significativas en un texto. La PMI mide la asociación entre dos términos y se calcula comparando la frecuencia observada de su co-ocurrencia con la frecuencia esperada si fueran independientes. Las colocaciones con una PMI alta se consideran palabras clave potenciales.
corpus_etiquetado$word <- tolower(corpus_etiquetado$token)
stats <- keywords_collocation(x = corpus_etiquetado, term = "word", group = "doc_id")
stats$key <- factor(stats$keyword, levels = rev(stats$keyword))
barchart(key ~ pmi, data = head(subset(stats, freq > 3), 20), col = "#b7c6d3",
main = "Discurso presidencial:
palabras clave identificadas por Colocación de PMI",
xlab = "PMI (Información Mutua Puntual)")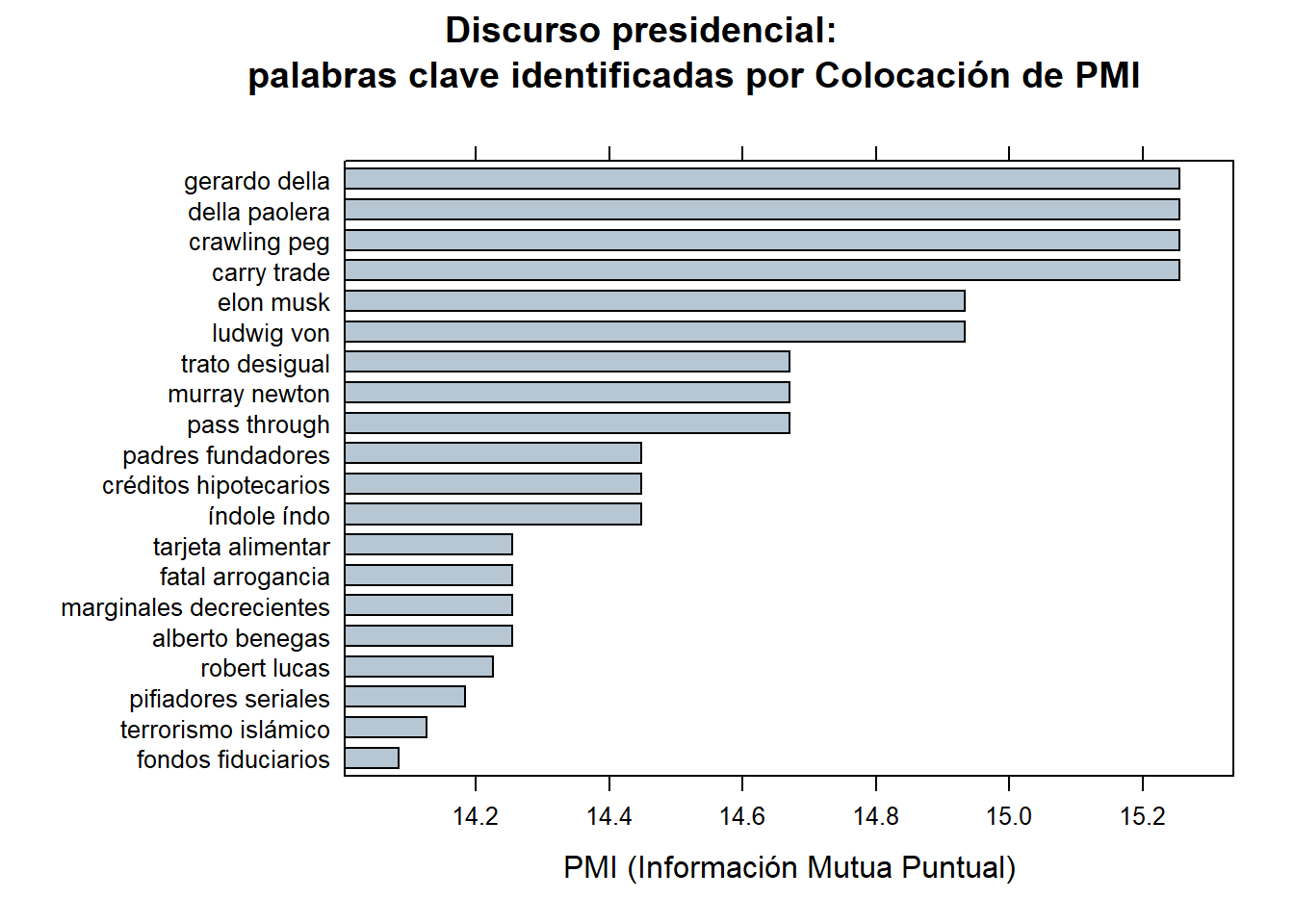
Este método se basa en la identificación de secuencias de partes del discurso que ocurren con frecuencia juntas en un texto. Por ejemplo, podría identificar combinaciones como “sustantivo + adjetivo” o “verbo + sustantivo”. Estas secuencias de partes del discurso pueden ser indicativas de frases significativas o construcciones gramaticales importantes en el texto.
Estos métodos son útiles para extraer automáticamente las palabras o frases más relevantes en un texto, lo que puede ayudar en tareas como el resumen automático, la clasificación de documentos o la extracción de información clave.
corpus_etiquetado$phrase_tag <- as_phrasemachine(corpus_etiquetado$upos,
type = "upos")
stats <- keywords_phrases(x = corpus_etiquetado$phrase_tag,
term = tolower(corpus_etiquetado$token),
pattern = "(A|N)*N(P+D*(A|N)*N)*",
is_regex = TRUE, detailed = FALSE)
stats <- subset(stats, ngram > 1 & freq > 3)
stats$key <- factor(stats$keyword, levels = rev(stats$keyword))
barchart(key ~ freq, data = head(stats, 20), col = "#bccfde",
main = "Discurso presidencial: Palabras clave - frases simples de sustantivos", xlab = "Frecuencia")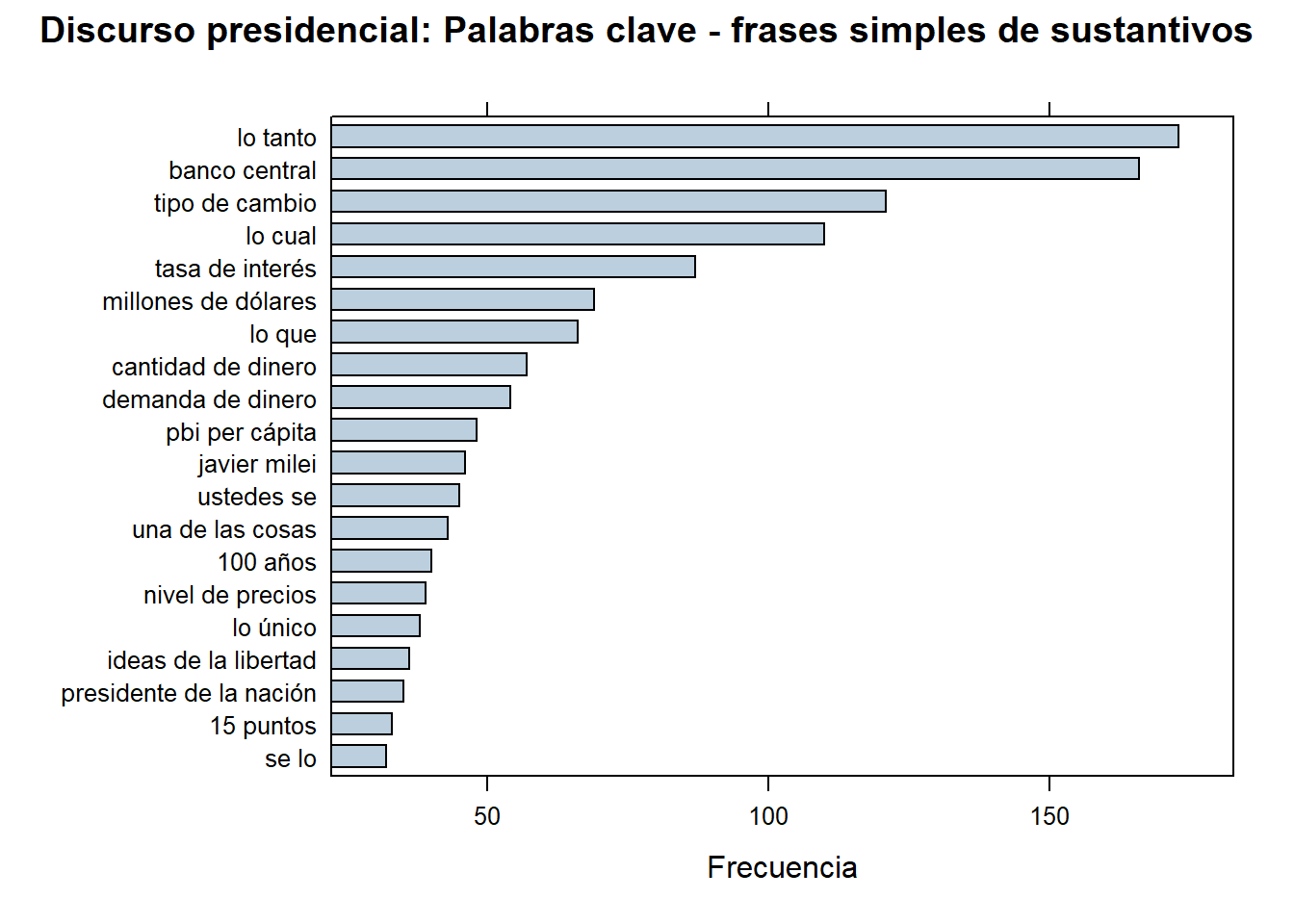
Las co-ocurrencias permiten ver cómo se utilizan las palabras ya sea en la misma oración o bien una al lado de la otra. Udpipe facilita la creación de gráficos de co-ocurrencia utilizando las etiquetas relevantes de partes del discurso.
Si estás interesado en visualizar qué palabras se siguen entre sí, esto se puede hacer calculando las co-ocurrencias de palabras de un tipo específico de partes del discurso que se siguen entre sí, donde puedes especificar qué tan lejos deseas buscar en relación con ‘seguirse’ (en el ejemplo a continuación indicamos skipgram = 1, lo que significa que mira la siguiente palabra y la palabra después de esa).
corpus_etiquetado$id <- unique_identifier(corpus_etiquetado, fields = c("sentence_id", "doc_id"))
dtm <- subset(corpus_etiquetado, upos %in% c("NOUN", "ADJ"))
dtm <- document_term_frequencies(dtm, document = "id", term = "lemma")
dtm <- document_term_matrix(dtm)
dtm <- dtm_remove_lowfreq(dtm, minfreq = 5)
termcorrelations <- dtm_cor(dtm)
y <- as_cooccurrence(termcorrelations)
y <- subset(y, term1 < term2 & abs(cooc) > 0.2)
y <- y[order(abs(y$cooc), decreasing = TRUE), ]
head(y) term1 term2 cooc
170300 artificial inteligencia 1.0000000
599266 desigual trato 0.9127832
99742 arrogancia fatal 0.8658589
152283 confortable incómodo 0.8449918
557900 preferencia tecnología 0.8386677
14069 analógico círculo 0.7998078Durante esta clase profundizamos en las técnicas esenciales para la extracción, procesamiento y exploración de datos de texto. Pusimos especial énfasis en el scraping web como una herramienta esencial para obtener datos de manera automatizada, resaltando su importancia ética y legal. A través de ejemplos prácticos, exploramos cómo el web scraping puede ser aplicado para recopilar información diversa, ofreciendo así un acceso valioso a datos no estructurados.
Además de enfocarnos en el potencial del web scraping, ampliamos nuestro conocimiento sobre técnicas avanzadas de procesamiento de lenguaje natural, como la lematización y el etiquetado morfosintáctico, utilizando la biblioteca udpipe. Estas técnicas resultan fundamentales para comprender la estructura y el significado del texto, proporcionando una base sólida para el análisis lingüístico.
Por último cabrá destacar que incorporamos de nuevos paquetes y funciones del mundo R, además de udpipe, interactuamos con herramientas como lattice para graficar y glue; que ofrece funcionalidades útiles para trabajar con textos de manera eficiente.
Esta clase 7 ha proporcionado una segunda capa de técnicas fundamentales para la recopilación u el análisis de datos de texto. A medida que avancemos, seguiremos explorando una variedad de herramientas para analizar el lenguaje natural, como el topic modeling y el análisis de sentimientos. Además, nos adentraremos en el uso de la inteligencia artificial para abordar problemas más complejos. Sin embargo, es crucial recordar que la selección de herramientas debe estar en concordancia con los objetivos de estudio y el proyecto de investigación específico de cada unx. Continuar aprendiendo y aplicando estas técnicas nos permitirá aprovechar al máximo el vasto potencial de los datos de texto en una variedad de campos y aplicaciones.
Se trata de técnicas rápidas y gratuitas para trabajar con texto.↩︎
La función map es parte del paquete purrr-tidyverse y se utiliza para aplicar una función a cada elemento de una lista (o vector) y retornar los resultados en una lista. Funciona de manera similar a un bucle, pero de forma más concisa y funcional. Más info en la documentación.↩︎
@online{damián_orden2024,
author = {Damián Orden, Pedro},
title = {Clase 7: {Extracción,} Procesamiento y Exploración de Datos
de Texto},
date = {2024-06-21},
url = {https://tecysoc.netlify.app/posts/discursos/},
langid = {en}
}