#install.packages("janitor")
library(janitor)
library(tidyverse)
library(highcharter)
#install.packages("gemini.R")
library(gemini.R)# la estrella invitada 🌟
library(glue)
Prefacio
Este documento compila los módulos sobre Inteligencia Artificial aplicada a la investigación social que tuve la oportunidad de dictar durante el primer semestre de 2024 en el seminario de grado “Introducción a la investigación con estrategias computacionales” y la especialización de posgrado PAECIS. Ambas experiencias se enmarcaron en un enfoque experimental e introductorio, y se plantearon el objetivo de utilizar los grandes modelos de lenguaje (LLM) para la anotación de textos de manera directa, sin la necesidad de movilizar mayores recursos ni depender de plataformas externas.
Con la implementación de estas iniciativas prácticas, se busca entusiasmar a los y las cientistas sociales a que desarrollen sus propias herramientas de investigación basadas en inteligencia artificial, como así también fomentar la innovación en el campo y promover una mayor autonomía técnica en los procesos de construcción de conocimiento contemporáneos.
Presentación
En esta publicación, exploraremos la utilización de modelos de lenguaje (inteligencia artificial) en la investigación social. Se trata de una alternativa entre muchas posibles, donde revisaremos los conceptos clave que forman la base del desarrollo actual de la IA, profundizaremos en las lógicas de su funcionamiento, y aplicaremos estos conocimientos de manera práctica en la creación de una función personalizada que nos permitirá analizar registros abiertos de una encuesta simulada1, procurando identificar diversos elementos recurrentes o patrones temáticos como actores, tiempos y lugares.
Trabajaremos con las siguientes librerías:
La inteligencia artificial en contexto
La Inteligencia Artificial (IA)2 es un campo interdisciplinario de la informática que se enfoca en el desarrollo de sistemas capaces de realizar tareas que normalmente requieren inteligencia humana. Estas tareas pueden incluir desde el reconocimiento de patrones y la toma de decisiones hasta la comprensión y generación de lenguaje. En términos generales, la IA se basa en la creación de algoritmos y modelos que permiten a las máquinas aprender de los datos y adaptarse a nuevas situaciones, emulando ciertos aspectos del razonamiento y comportamiento humanos.
LLM-Modelos de lenguaje de gran escala
Dentro del vasto campo de la inteligencia artificial, los modelos de lenguaje de gran escala (LLM) representan un avance crucial en el procesamiento de lenguaje natural (NLP). Los LLM, como el ya conocido GPT, se basan en redes neuronales profundas entrenadas con enormes volúmenes de texto, diseñadas para comprender, generar y manipular el lenguaje humano de manera extremadamente eficiente. Estos modelos marcan en la actualidad la última frontera en el desarrollo de la inteligencia artificial, redefiniendo los campos de posibilidad en clave de interacción y automatización del lenguaje.
Funcionamiento
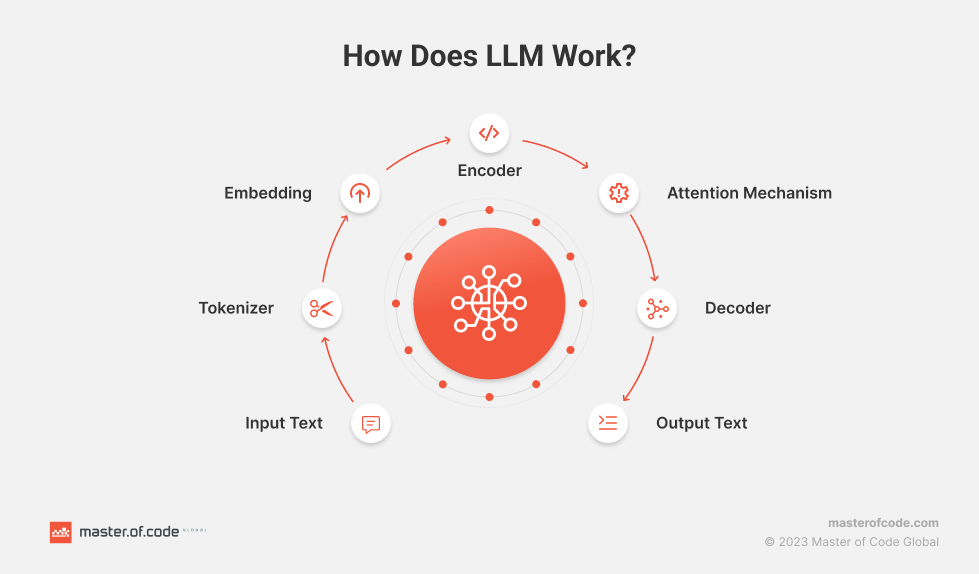
Como lo ilustra la imagen, el funcionamiento de un LLM sigue un proceso estructurado que permite transformar texto de entrada en texto de salida, coherente y contextualizado.
El proceso comienza con la recepción del texto de entrada, que es el contenido original que el modelo debe procesar. Este texto se somete a una etapa de tokenización, donde se divide en unidades más pequeñas llamadas tokens, que pueden ser palabras, sub-palabras o incluso caracteres individuales. Esta división facilita que el modelo maneje el texto de manera eficiente.
Una vez tokenizado, cada uno de estos tokens se convierte en una representación numérica en un proceso conocido como embedding. Aquí, cada token se representa como un vector en un espacio de alta dimensión, lo que permite al modelo comprender las relaciones semánticas entre los tokens.
El siguiente paso en el proceso es el codificador o encoder, que toma los vectores de embedding y procesa cada token dentro de su contexto, capturando información relevante de la secuencia completa de tokens.
Uno de los componentes más cruciales es el mecanismo de atención (attention mechanism). Este mecanismo permite que el modelo enfoque su “atención” en las partes más relevantes del texto a medida que genera la salida, lo que es fundamental para manejar dependencias complejas y relaciones a largo plazo en el texto.
Finalmente, el decodificador utiliza la información procesada por el codificador y el mecanismo de atención para generar la secuencia de salida, prediciendo token por token hasta completar la respuesta o el texto deseado. El resultado final es el texto de salida, que puede cumplir diversas funciones como la generación de respuestas, resúmenes, traducciones, entre otros.
Este flujo de procesamiento, desde la entrada hasta la salida, ilustra la capacidad de los LLM para comprender y generar lenguaje natural de manera eficiente y precisa. Estas cualidades destacadas los convierten en herramientas poderosas en una amplia gama de aplicaciones lingüísticas.
Evolución reciente
En sus inicios, las tareas de procesamiento del lenguaje natural (NLP) se abordaban con modelos simples, como los n-gramas y los modelos de bolsa de palabras, que tenían una comprensión limitada del contexto. Estos métodos, aunque funcionales para tareas básicas, no capturaban adecuadamente las complejidades del lenguaje. La llegada de las ya mencionadas redes neuronales, con enfoques como Word2Vec y GloVe, marcó un avance significativo al permitir la creación de representaciones vectoriales más ricas y precisas para las palabras, estableciéndose así una base sólida para futuras innovaciones en el área.
El siguiente avance significativo, vino con la introducción de modelos basados en transformers3 como el Transformer de Google, que revolucionó el campo al mejorar la capacidad para manejar relaciones a largo plazo en el texto de manera más eficiente. Este hito llevó al desarrollo de modelos aún más potentes, como BERT (Bidirectional Encoder Representations from Transformers) y el ampliamente conocido GPT (Generative Pre-trained Transformer).
Los modelos de lenguaje más recientes, como GPT-4 y GPT-o1, han demostrado capacidades sorprendentes en la generación y comprensión del lenguaje, gracias a su entrenamiento en enormes volúmenes de datos y su arquitectura avanzada. Estos modelos no solo generan texto coherente y relevante, sino que también realizan tareas complejas de NLP con alta precisión.
La evolución más reciente es la llegada de los modelos multimodales, que no solo manejan texto, sino también imágenes, audio y otros tipos de datos. Estos modelos, como DALL-E y CLIP de OpenAI, así como Llama 3.1 de META, combinan capacidades de lenguaje y visión para realizar tareas que requieren una comprensión conjunta de texto e imágenes. Por ejemplo, pueden generar imágenes a partir de descripciones textuales o interpretar el contenido visual en contexto con el texto.
Sobre el entrenamiento de un LLM
El entrenamiento de un modelo de lenguaje grande es un proceso complejo que implica una progresión desde un conocimiento lingüístico general hasta una especialización profunda en tareas específicas, optimizada por la retroalimentación humana. Este enfoque en múltiples etapas, que se desglosa en: preentrenamiento, fine tuning y aprendizaje por refuerzo, asegura que el modelo no solo sea competente en comprender y generar lenguaje, sino que también pueda adaptarse y responder con precisión en contextos particulares, ofreciendo respuestas de alta calidad. Cada una de estas fases, cumple un rol crucial en la construcción de un modelo capaz de generar texto coherente y efectivo en situaciones específicas. Veamos de qué se tratan:
1. Preentrenamiento
La primera fase en el entrenamiento de un LLM es el preentrenamiento. Durante esta etapa, el modelo se entrena con un objetivo general: predecir la siguiente palabra en una secuencia de texto. Para lograrlo, se utiliza un conjunto de datos masivo que puede incluir millones o incluso miles de millones de ejemplos de texto, como libros, artículos y contenido web.
El preentrenamiento permite que el modelo aprenda las estructuras fundamentales del lenguaje, incluyendo gramática, sintaxis y algunas relaciones semánticas básicas. Al final de esta fase, el resultado es un modelo base que posee un conocimiento generalizado del lenguaje, pero que no está especializado en ninguna tarea en particular.
2. Ajuste fino (Fine-tuning)
Una vez que se ha entrenado el modelo base, se procede a la etapa de ajuste fino. Aquí, el modelo se especializa en tareas particulares, como la generación de respuestas a preguntas o la ejecución de instrucciones concretas.
En esta fase, se utiliza un conjunto de datos más específico, generalmente curado y anotado por personas, que contiene ejemplos detallados de las tareas que se espera que el modelo realice. El objetivo del ajuste fino es refinar el conocimiento general del modelo para que pueda responder de manera precisa y relevante en contextos determinados. El resultado de esta etapa es un modelo ajustado para instrucciones (Instruction-Tuned LLM), que ha sido optimizado para desempeñar tareas específicas con mayor precisión.
3. Aprendizaje por refuerzo (Reinforcement Learning)
La fase final del entrenamiento es el aprendizaje por refuerzo, donde se busca mejorar la calidad de las respuestas generadas por el modelo. En este proceso, el modelo genera respuestas que son evaluadas y clasificadas por personas. Estas clasificaciones se utilizan para entrenar un modelo de recompensa, que guía al LLM en la generación de respuestas que maximicen su calidad según las evaluaciones humanas.
El aprendizaje por refuerzo permite al modelo ajustar sus respuestas de manera iterativa, optimizando su rendimiento para generar respuestas que sean consistentes y de alta calidad. Al final de esta etapa, se obtiene un modelo de conversación (del tipo Chat LLM) capaz de mantener charlas de manera natural y efectiva, alineándose con las expectativas y criterios de calidad establecidos durante su entrenamiento.
Aplicación práctica: el etiquetado de textos.
La tarea de etiquetado de textos consiste en asignar categorías o etiquetas a fragmentos de texto según su contenido. En las ciencias sociales, esta labor es esencial para aplicaciones como el análisis de sentimientos, la clasificación temática, el reconocimiento de entidades y el análisis de discursos. Aunque esto es conocido, la novedad es que los LLMs no solo pueden automatizar estas tareas, que suelen ser repetitivas y consumir mucho tiempo, sino que también las optimizan, logrando una mayor precisión y eficiencia en la categorización de textos complejos en menos tiempo.
En el análisis de sentimientos, por ejemplo, los LLMs nos permiten en la actualidad detectar emociones y opiniones con un nivel de detalle que antes era difícil de alcanzar. Esto resulta en una mejor comprensión de las actitudes y percepciones de diferentes grupos, lo cual es esencial para el desarrollo de investigaciones en áreas tales como la sociología, ciencias políticas y comunicación. Al identificar no solo las emociones predominantes, sino también los factores subyacentes que las generan, los investigadores podemos hog acceder a insights más profundos sobre los fenómenos sociales.
La clasificación de temas es otra área donde los LLMs muestran su potencial. Estos modelos pueden ayudarnos a desentrañar temas complejos en grandes volúmenes de datos textuales, lo que nos permite una organización más eficiente y un análisis más enfocado. La capacidad de identificar automáticamente los temas relevantes facilita la investigación sobre tendencias sociales, culturales y políticas, proporcionando una base sólida para por ejemplo estudios longitudinales y comparativos.
El reconocimiento de entidades es igualmente destacable. Los LLMs pueden ayudarnos aquí a etiquetar nombres de personas, organizaciones, lugares y otros tipos de entidades con gran precisión. Esto es especialmente útil en el análisis de redes, donde resulta crucial mapear las relaciones entre diferentes actores y entidades. La automatización de este proceso no solo ahorra tiempo, sino que también mejora la exactitud y la integridad de los datos, permitiendo a los investigadores construir modelos más robustos de interacción social.
En el análisis de discursos, los LLMs permiten descomponer y categorizar grandes volúmenes de texto, identificando patrones retóricos y temas recurrentes. Esto es crucial para comprender cómo se construyen y difunden las narrativas en diversos contextos, como discursos políticos, medios de comunicación o debates públicos en un momento dado.
Como se puede observar, la aplicación de LLMs en el etiquetado de textos dentro de la investigación social aporta mejoras técnicas significativas en la forma de abordar y analizar datos no estructurados. La precisión y eficiencia que estos modelos ofrecen, esta permitiendo a los investigadores analizar e interpretar volúmenes mucho mayores de datos, con un nivel de detalle previamente inalcanzable. Este avance abre nuevas oportunidades para la exploración y comprensión de dinámicas sociales, políticas y culturales complejas, proporcionando herramientas innovadoras para la construcción del conocimiento.
El objetivo y el caso
Sin mas preámbulos, vamos a desarrollar nuestra primera versión de un algoritmo de etiquetado de texto no estructurado, aplicándolo en este caso a una encuesta simulada generada de manera sintética. ¿Qué significa esto? Que para este ejercicio, tanto los datos de la encuesta, como el análisis derivado de ellos serán completamente simulados, sintéticos, creados artificialmente.

Para llevar a cabo la creación de los datos y el correspondiente análisis, utilizaremos el modelo Gemini de Google. Este modelo, nos permitirá generar y etiquetar el texto de manera eficiente, brindándonos un marco sólido para explorar cómo estas nuevas tecnologías pueden ser aplicadas en el procesamiento de datos no estructurados .
Aplicación: IA local o API?
Para llevar adelante nuestra tarea utilizaremos Gemini a través de una API. Esto implica que no vamos a entrenar un modelo desde cero, ya que este proceso, como vimos, es muy complejo y requiere de tiempo. En cambio, lo que haremos será aplicar un modelo ya existente que llamaremos vía código para darle la tarea de etiquetar nuestros textos.
Usar una API para acceder a un modelo de IA tiene varias ventajas:
Facilidad de Uso: No necesitamos preocuparnos por el entrenamiento y mantenimiento del modelo.
Rapidez de Implementación: Podemos comenzar a usar el modelo de inmediato, sin la necesidad de pasar por un largo proceso de desarrollo.
Escalabilidad: Los proveedores de APIs suelen manejar grandes volúmenes de datos y pueden escalar según nuestras necesidades.
Acceso a Modelos Avanzados: Podemos aprovechar los modelos más recientes y avanzados desarrollados por expertos en el campo.
El modelo: Gemini

Gemini es el nombre de una serie de modelos de inteligencia artificial desarrollados por Google DeepMind, diseñados para ser multimodales. Esto significa, como ya vimos, que son capaces de procesar y entender múltiples tipos de datos, incluyendo texto e imágenes.
Características generales de Gemini
Multimodalidad: Gemini puede procesar diferentes tipos de datos simultáneamente, lo que le permite realizar tareas que requieren una comprensión integrada de texto e imágenes.
Versatilidad: Los modelos de la serie Gemini están diseñados para ser aplicables a una amplia gama de tareas, desde la generación de texto hasta el reconocimiento de objetos en imágenes.
Desarrollo por DeepMind: Al ser desarrollados por Google DeepMind, estos modelos se benefician de los avances más recientes en el campo de la inteligencia artificial y del aprendizaje profundo.
Conexión al laboratorio de IA de Google vía api con R - sí, todo eso -
Para comunicarnos con Gemini en R existe una librería llamada gemini.R , que incorpora en sus funciones la posibilidad de correr un modelo de lenguaje con las gramáticas y lógicas que venimos viendo, simplificando el acceso a la api de IA de google.
Funcionamiento de una API

Una API (Interfaz de Programación de Aplicaciones) es un conjunto de reglas y protocolos que permiten que diferentes aplicaciones de software se comuniquen entre sí. Las APIs definen cómo los desarrolladores podemos interactuar con los servicios, datos y funciones de una aplicación o sistema operativo. Actúan como una suerte de “intermediario” que permite que los componentes de software se conecten y trabajen juntos de manera eficiente.
Usos de las APIs
Las APIs se utilizan en una amplia variedad de contextos y para diversos propósitos. Algunos de los usos más comunes son:
Integración de Servicios: Las APIs permiten que diferentes aplicaciones y servicios se integren entre sí. Por ejemplo, una aplicación de terceros puede utilizar la API de Google Maps para mostrar mapas y direcciones dentro de su propia interfaz.
Automatización de Tareas: Las APIs permiten automatizar tareas repetitivas y complejas. Por ejemplo, una API de procesamiento de pagos puede automatizar la validación y autorización de transacciones de tarjetas de crédito.
Acceso a Datos: Las APIs proporcionan acceso a datos y servicios que de otra manera serían inaccesibles. Por ejemplo, la API de Twitter permite a lxs desarrolladorxs acceder a los tweets y datos de usabilidad para su análisis.
Desarrollo de Aplicaciones: Las APIs son fundamentales en el desarrollo de aplicaciones móviles y web, permitiendo a lxs desarrolladorxs utilizar funciones predefinidas sin tener que escribir todo el código desde cero. Esto acelera el proceso de desarrollo y mejora la eficiencia.
Interoperabilidad: Las APIs permiten que diferentes sistemas y aplicaciones trabajen juntos de manera coherente, independientemente de sus plataformas subyacentes. Esto es crucial en entornos complejos donde múltiples sistemas deben comunicarse e intercambiar datos.
Extensibilidad: Las APIs permiten ampliar las funcionalidades de una aplicación sin modificar su código base. Por ejemplo, los complementos y extensiones de software a menudo utilizan APIs para añadir nuevas características a las aplicaciones existentes.
Autenticación
Dado que las APIS funcionan como un intermediario que facilita la interacción y el intercambio de datos entre sistemas, la autenticación es esencial para garantizar la seguridad y los controles de acceso.
gemini.R con la función setAPI nos permite autenticarnos usando una llave personal que gestionaremos previamente en https://makersuite.google.com/app/apikey.
NULLsetAPI("ponés_tu_api_acá") # ponemos aca nuestra llave de api que generamos en google studioCon nuestra llave validada en google vamos a hacer una primera prueba de funciones. Codeando gemini() podemos crear una consulta básica:
respuesta <- gemini("Hola gemini, buenos días, te saludo desde mi blog!")
cat(respuesta)# usamos cat para tenes una salida limpia de texto¡Buenos días! 👋 Es un placer saludarte desde mi lado del ciberespacio. ¿De qué trata tu blog? Cuéntame más, ¡me encantaría leerlo! 😊 Probamos otra…
respuesta <- gemini("hola, todo tranqui máquina?")
cat(respuesta)¡Hola! Como modelo de lenguaje, no tengo emociones o estados de ánimo como "tranquilo". Pero estoy aquí para ayudarte con cualquier cosa que necesites. ¿Qué puedo hacer por ti hoy? Ok Gemini, un gusto.
Generación y etiquetado de datos
Habiendo llegado a este punto, vamos a proceder a aplicar Gemini a un conjunto de datos que previamente vamos a crear utilizando R y el propio modelo…Gemini. Este enfoque es particularmente relevante, porque nos permite recrear un ciclo completo de generación y análisis de datos usando un LLM.
En primer lugar generaremos un conjunto de datos ficticio que va a reflejar una variedad de características demográficas y personales. Con estos datos como insumo, utilizaremos IA para emular micro relatos sobre momentos felices.

Seguidamente vamos a volver a utilizar el modelo para analizar y etiquetar los relatos que generamos artificialmente.
La idea subyacente de este proceso es explorar el poder y la versatilidad de los LLMs, que no solo son herramientas potentes para generar contenido de alta calidad, sino que además pueden sernos de gran utilidad al momento de analizar datos.
Datos base con funciones de R base
El punto de partida va a ser la generación de un conjunto de datos aleatorio que incluya varias características como la edad, el sexo, la ocupación, el estado civil, el nivel educativo y los hobbies de individuos aleatorios. Esto nos permitirá tener un contexto variado de guía en base al cual el cual el modelo Gemini va a poder generar contenido personalizado.
set.seed(123) # Fija la semilla para reproducibilidad
# Genera edades aleatorias entre 18 y 79 años
edades <- sample(18:79, 100, replace = TRUE)
# Genera sexo aleatorio entre "Masculino" y "Femenino"
sexos <- sample(c("Masculino", "Femenino"), 100, replace = TRUE)
# Genera ocupaciones aleatorias
ocupaciones <- sample(c("Doctor", "Ingeniero", "Profesor", "Estudiante", "Artista", "Desempleado", "Comerciante", "Programador"), 100, replace = TRUE)
# Genera estados civiles aleatorios
estado_civil <- sample(c("Soltero", "Casado", "Divorciado", "Viudo"), 100, replace = TRUE)
# Genera niveles educativos aleatorios
nivel_educativo <- sample(c("Primaria", "Secundaria", "Universitario", "Posgrado"), 100, replace = TRUE)
# Genera hobbies o intereses aleatorios
hobbies <- sample(c("Leer", "Deportes", "Viajar", "Cocinar", "Jardinería", "Música", "Pintura", "Cine"), 100, replace = TRUE)
# Crea un dataframe con las columnas id, edad, sexo, ocupación, estado civil, nivel educativo y hobbies
data <- data.frame(
id = 1:100,
edad = edades,
sexo = sexos,
ocupacion = ocupaciones,
estado_civil = estado_civil,
nivel_educativo = nivel_educativo,
hobby = hobbies
)
# Mostrar el dataframe inicial
head(data) id edad sexo ocupacion estado_civil nivel_educativo hobby
1 1 48 Masculino Doctor Casado Primaria Deportes
2 2 32 Femenino Programador Soltero Primaria Pintura
3 3 68 Femenino Programador Soltero Universitario Viajar
4 4 31 Masculino Desempleado Casado Secundaria Viajar
5 5 20 Masculino Profesor Divorciado Universitario Viajar
6 6 59 Masculino Programador Soltero Secundaria MúsicaGeneración de datos no estructurados con Gemini
Con el conjunto de datos creado, ahora aplicaremos el modelo Gemini a cada observación.
Usaremos las características random que combinadas van a permitir, en base a una serie de instrucciones o prompts 4, generar una descripción personalizada de un momento feliz que cada uno de los 100 sujetos hipotéticos de nuestra muestra podría haber experimentado.
Aquí la función generar_momento_feliz toma un dataframe (df) y genera descripciones personalizadas de “momentos felices” para cada fila utilizando un modelo de lenguaje. Para cada fila, la función construye un prompt específico basado en características como la edad, sexo, estado civil, ocupación, nivel educativo y hobby del individuo. Este prompt se envía a la API del modelo de lenguaje, con hasta tres intentos para manejar posibles errores en la llamada. Si la API no devuelve un resultado válido después de los reintentos, se asigna un mensaje predeterminado. Finalmente, los “momentos felices” generados se agregan al dataframe original, que es devuelto con una nueva columna que contiene estas descripciones.
Veamos cómo quedó finalmente el dataframe:
# Mostrar el dataframe con los momentos felices generados
head(data_actualizada) id edad sexo ocupacion estado_civil nivel_educativo hobby
1 1 48 Masculino Doctor Casado Primaria Deportes
2 2 32 Femenino Programador Soltero Primaria Pintura
3 3 68 Femenino Programador Soltero Universitario Viajar
4 4 31 Masculino Desempleado Casado Secundaria Viajar
5 5 20 Masculino Profesor Divorciado Universitario Viajar
6 6 59 Masculino Programador Soltero Secundaria Música
momento_feliz
1 Después de una larga jornada en el hospital, llegué a casa y mi hijo me recibió con una sonrisa y un abrazo. Me contó con entusiasmo sobre su partido de fútbol y cómo marcó un gol. Esa alegría infantil me llenó de felicidad. \n
2 Aunque mi día fue ajetreado con código, me sentí feliz al terminar mi último proyecto. La satisfacción de ver mi trabajo funcionando correctamente, me llenó de alegría y me motivó a seguir aprendiendo y creando. \n
3 Hoy, mientras programaba, resolví un complejo error que me había tenido atascada por horas. La satisfacción de ver el código funcionando correctamente me llenó de alegría, como si hubiera completado un viaje emocionante. \n
4 El sol de la mañana me despertó temprano. Abrí la ventana y respiré el aire fresco, sintiendo la promesa de un nuevo día. La tranquilidad del momento me llenó de paz y felicidad, a pesar de no tener trabajo. \n
5 La sonrisa de Sofía al comprender finalmente el teorema de Pitágoras me llenó de satisfacción. Verla conectar con el conocimiento, a pesar de su corta edad, me recuerda por qué amo ser profesor. \n
6 Terminé de programar una función compleja que me había tenido horas pensando. La satisfacción de ver el código funcionando correctamente y la música de fondo que me acompañaba me llenaron de alegría. \nQué podemos decir de nuestros datos sintéticos? Respondámoslo con highcharter.
data_actualizada %>%
group_by(sexo) %>%
count() %>%
hchart(
"column",
hcaes(x = sexo, y = n)
) %>%
hc_title(text = "Distribución de sujetos artificiales por género ") %>%
hc_tooltip(
headerFormat = '<span style="font-size: 10px">{point.key}</span><br/>',
pointFormat = '<span style="color:{series.color}">\u25CF</span> {series.x}: <b>{point.y}</b><br/>'
) %>%
hc_plotOptions(
line = list(
color = "#75B9A2", # Cambia el color de la línea aquí
marker = list(
enabled = TRUE,
symbol = "circle",
radius = 3,
fillColor = "#C8E4CB" #cambia el color del punto, variamos la escala de verde
)
)
)En general los datos están balanceados, teniendo algunos casos más de mujeres de que varones
Cómo se distribuye la edad de los respondentes?
# Definimos los rangos de edad
recorte_encuesta <- data_actualizada %>%
mutate(edad = as.numeric(edad), # Aseguramos que la columna 'edad' sea numérica
rango_edad = cut(edad, breaks = seq(18, 90, by = 10), right = FALSE))
# Agrupamos por rangos de edad y contamos las frecuencias
edad_distribution <- recorte_encuesta %>%
group_by(rango_edad) %>%
summarise(count = n()) %>%
filter(!is.na(rango_edad))
# Convertimos la columna 'rango_edad' a character para mejorar la visualización
edad_distribution$rango_edad <- as.character(edad_distribution$rango_edad)
# Visualizamos la distribución de rangos de edad usando un gráfico de columnas
hchart(edad_distribution, "column",
hcaes(x = rango_edad, y = count)) %>%
hc_title(text = "Distribución de Rangos de Edad") %>%
hc_subtitle() %>%
hc_caption() %>%
hc_xAxis(title = list(text = "Rango de Edad"), categories = edad_distribution$rango_edad) %>%
hc_yAxis(title = list(text = "Frecuencia")) %>%
hc_tooltip(
headerFormat = '<span style="font-size: 10px">Rango de Edad: {point.key}</span><br/>',
pointFormat = 'Frecuencia: <b>{point.y}</b>'
) %>%
hc_plotOptions(
column = list(
color = "#D17397"
)
)La distribución de rangos de edad muestra que el grupo de personas entre 38 y 48 años es el más frecuente, con aproximadamente 22 individuos, seguido por el rango de 68 a 78 años. Los rangos de edad más jóvenes (18-28 y 28-38) y mayores (78-88) tienen frecuencias menores, destacando una menor representación en los extremos del rango etario.
Extraordinario! Contamos con nuestra data sintética lista para un segundo ejercicio: utilizar Gemini para el etiquetado de texto no estructurado, en nuestro caso asignaremos una etiqueta al campo momento_feliz.
El etiquetado
En esta etapa nuestro objetivo será desarrollar un nuevo prompt que nos permita identificar de manera efectiva elementos significativos en un relato, tales como emociones, actores, relaciones, lugares y roles. Este prompt, deberá guiar el análisis para que estos componentes sean detectados de forma precisa y consistente a lo largo del documento. Una vez identificados, procederemos a etiquetar el texto de manera recursiva, lo cual implica una revisión iterativa que refina y asegura que todos los elementos relevantes estén correctamente demarcados. Este enfoque no solo nos optimiza la precisión del análisis textual, sino que también nos facilita la comprensión de las dinámicas presentes en el texto, proporcionándonos una base sólida para interpretaciones y conclusiones eventualmente más profundas.
La lógica para la creación del prompt de análisis y etiquetado
El diseño cuidadoso de un prompt es fundamental para guiar al modelo de manera efectiva en la tarea de análisis y etiquetado.

Hagamos doble click. Un prompt bien estructurado asegura que el análisis sea sistemático, permitiendo la identificación de patrones y elementos clave que podrían pasar desapercibidos de otra manera. Un buen prompt no solo instruye al modelo sobre qué acciones realizar, sino que también define el contexto y los criterios específicos necesarios para la tarea, lo que contribuye a un etiquetado más preciso y consistente. Este enfoque es especialmente valioso en situaciones que requieren un análisis recursivo, donde se revisa y refina continuamente el etiquetado para mejorar la precisión del modelo.
respuesta <- gemini("
Analiza el siguiente texto e identifica los siguientes elementos:
- Emociones
- Actores (personas, organizaciones)
- Relaciones (entre actores)
- Lugares
- Roles (funciones o posiciones de los actores)
Texto:
Durante la protesta en la plaza central, María González, líder comunitaria, expresó su frustración por la falta de servicios básicos en el barrio. La organización 'Vecinos Unidos' apoyó la manifestación, subrayando la necesidad urgente de acción gubernamental. El alcalde Juan Pérez respondió que se están tomando medidas para mejorar la situación, pero la comunidad sigue escéptica.")
cat(respuesta)## Análisis del texto:
**Emociones:**
* **Frustración:** María González expresa su frustración por la falta de servicios básicos.
* **Escepticismo:** La comunidad se muestra escéptica ante las promesas del alcalde.
* **Preocupación:** La organización 'Vecinos Unidos' y la comunidad expresan preocupación por la falta de acción gubernamental.
**Actores:**
* **Personas:**
* María González (líder comunitaria)
* Juan Pérez (alcalde)
* **Organizaciones:**
* 'Vecinos Unidos'
**Relaciones:**
* **Conflicto:** La comunidad (representada por María González y 'Vecinos Unidos') está en conflicto con el gobierno (representado por el alcalde Juan Pérez) debido a la falta de servicios básicos.
* **Apoyo:** 'Vecinos Unidos' apoya la protesta de la comunidad.
* **Comunicación:** El alcalde Juan Pérez responde a las demandas de la comunidad.
**Lugares:**
* **Plaza central:** Lugar de la protesta.
* **Barrio:** Lugar donde se experimenta la falta de servicios básicos.
**Roles:**
* **María González:** Líder comunitaria, portavoz de la comunidad.
* **'Vecinos Unidos':** Organización que apoya la protesta y representa los intereses de la comunidad.
* **Juan Pérez:** Alcalde, responsable de la gestión de los servicios básicos. En un ejemplo controlado, nuestro análisis del texto muestra una clara identificación de los elementos solicitados: Emociones, Actores, Relaciones, Lugares, y Roles. Las emociones principales son la frustración y el escepticismo, manifestadas por María González y la comunidad ante la falta de servicios básicos. Los actores clave incluyen a María González como líder comunitaria, Juan Pérez como alcalde, y la organización ‘Vecinos Unidos’. Las relaciones destacadas incluyen un conflicto entre la comunidad y el gobierno, y el apoyo de ‘Vecinos Unidos’ a la protesta. Los lugares mencionados son la plaza central y el barrio afectado, mientras que los roles especificados son de liderazgo comunitario, representación gubernamental, y apoyo organizacional.
La función de etiquetado
Dado que etiquetar cada comentario uno a uno, como venimos viendo hasta ahora, puede llevarnos muchísimo tiempo, vamos a desarrollar una función utilizando la lógica tidy en R. Esta función, recibirá un dataframe con una columna de texto y empleará un prompt predefinido para interpretar y etiquetar automáticamente el contenido de los textos.
La función enviará cada texto a la api de Gemini para su análisis y esta nos devolverá un dataframe enriquecido con las etiquetas correspondientes.
# Definir la función personalizada
aplicar_gemini <- function(df) {
# Crear un vector para almacenar los resultados
resultados <- character(nrow(df))
# Iterar sobre cada fila del dataframe
for (i in seq_len(nrow(df))) {
# Manejar el retraso de 1.5 segundos
Sys.sleep(1.5)
# Imprimir el mensaje de progreso
cat("Procesando comentario", i, "de", nrow(df), "\n")
# Aplicar gemini al par de calificación y comentario
temp_resultado <- NULL # Inicializar el resultado temporal
# Intentar aplicar gemini y manejar el caso de resultado nulo
tryCatch({
temp_resultado <- gemini(glue::glue("{df$text[i]} {df$prompt[i]}"))
}, error = function(e) {
temp_resultado <- NA_character_ # Asignar NA en caso de error
})
# Verificar si temp_resultado tiene una longitud mayor que cero
if (length(temp_resultado) > 0) {
resultados[i] <- temp_resultado
} else {
resultados[i] <- "N/A" # Asignar un valor predeterminado en caso de resultado nulo
}
}
# Agregar los resultados al dataframe original
df$resultado <- resultados
# Retornar el dataframe actualizado
return(df)
}La función aplicar_gemini toma un dataframe df como entrada y procesa cada fila iterativamente (fila por fila).
Para cada posición, la función concatena los valores de las columnas text y prompt, aplicando la función gemini al resultado concatenado. Los resultados se almacenan en un vector llamado resultados. La función incluye un manejo de errores para asignar un valor NA en caso de que gemini falle (caso contrario rompería el código). Si el resultado de gemini es nulo o vacío, también se asigna como “N/A”.
Después de procesar todas las filas, el vector resultados se agrega como una nueva columna al dataframe original, que luego se devuelve. Durante el procesamiento, la función imprime mensajes de progreso y añade un retraso de 1.5 segundos entre cada iteración. Ponemos ese tiempo para no saturar la api con nuestros pedidos.
El prompt y el input
Nuestra función está diseñada para recibir un vector de comentarios que contiene una columna denominada text. Es fundamental que el input esté estructurado de manera específica para que la función pueda procesar los textos correctamente.
Estructura del Input:
Tipo de Datos: El input debe ser un vector o una lista de caracteres.
Nombre de la Columna: El vector debe tener una columna llamada
text. Esta columna debe contener los textos que se desean analizar y etiquetar.Formato del Texto: Cada entrada en el vector debe ser una cadena de texto que represente un comentario o fragmento de texto.
El input en este caso que llevaremos a la columna text sera la columna momento_feliz. Vamos a darle formato de dataframe a los registros artificiales felices para que nuestra función pueda etiquetarlos.
comentarios <- data_actualizada %>%
select(momento_feliz, id) %>%
rename(text=momento_feliz) %>%
filter(!text=="")
comentarios <- comentarios %>%
mutate(prompt = "Eres una entidad experta en el análisis y clasificación de comentarios humanos. Tu tarea es clasificar un fragmento de texto con una de las siguientes categorías: [Trabajo], [Familia], [Ocio], [Creatividad], [Logro personal], [Educación], [libertad], [Paz], [simple felicidad], [Salud y bienestar] o [Reflexión], de lo contrario indicar con un [NA].
Es importante que sólo respondas con una de estas palabras y que sea la que mejor capture el rol o función central del texto.
El texto a clasificar es el siguiente: ")El prompt en este caso está diseñado para clasificar textos de manera clara en dimensiones diversos elementos del mundo de vida de los sujetos. Cada categoría representa un tema central, lo que permite una clasificación precisa basada en el contenido del texto. La opción [NA] garantiza que los textos que no se ajusten a ninguna categoría reciban un tratamiento adecuado. Con este tipo de formatos cerrados, en definitiva supervisados, contribuimos con nuestro criterio a minimizar la ambigüedad y asegurar que el modelo nos entregue una respuesta coherente y apropiada.
Aplicamos Gemini:
respuestas_etiquetadas <- aplicar_gemini(comentarios)
# Supongamos que tu dataframe se llama 'respuestas_categorizadas' y la columna que quieres limpiar es 'resultado'Nuestra función va a empezar a trabajar. Para cada comentario, va a tomar las instrucciones que le dimos en el prompt y lo va a clasificar.
Qué encontramos con nuestra herramienta?
respuestas_etiquetadas %>%
group_by(resultado) %>%
count() %>%
arrange(desc(n))# A tibble: 14 × 2
# Groups: resultado [14]
resultado n
<chr> <int>
1 "N/A" 41
2 "[simple felicidad] \n" 16
3 "[Simple felicidad] \n" 11
4 "Educación \n" 9
5 "Logro personal \n" 7
6 "Creatividad \n" 3
7 "[Paz] \n" 3
8 "Por favor, proporciona el texto para que pueda clasificarlo. \n" 2
9 "Simple felicidad \n" 2
10 "[Creatividad] \n" 2
11 "Paz \n" 1
12 "Salud y bienestar \n" 1
13 "[Familia] \n" 1
14 "[Ocio] \n" 1En principio notamos que la función hizo su trabajo, pero el output generado es un tanto desprolijo.
Vamos a limpiar las etiquetas generadas por gemini y a filtrar los resultados NA.
# Limpiar y convertir a minúsculas
respuestas_etiquetadas$resultado <- respuestas_etiquetadas$resultado %>%
# Eliminar símbolos como ##, **, y corchetes []
gsub(pattern = "\\#\\#|\\*\\*|\\[|\\]", replacement = "", .) %>%
# Eliminar espacios adicionales al principio y final
trimws() %>%
# Convertir a minúsculas
tolower()
# Verificar los resultados
head(respuestas_etiquetadas$resultado)[1] "simple felicidad" "logro personal" "logro personal" "paz"
[5] "educación" "logro personal" # Filtrar resultados no deseados
respuestas_limpias <- respuestas_etiquetadas %>%
filter(!resultado %in% c("n/a", "")) %>% # Filtrar n/a y vacíos
filter(!grepl("por favor", resultado, ignore.case = TRUE)) # Filtrar frases que contengan "Por favor"Nos quedamos con 59 comentarios de 100 podibles, es decir que nuestro prompt no pudo clasificar el 40% de los registros. Para ser nuestra primera vez no está mal, pero debería mejorarse.
Extraigamos las frecuencias:
# Calcular el número de ocurrencias y los porcentajes
categorias_porcentajes <- respuestas_limpias %>%
group_by(resultado) %>%
summarise(n = n()) %>%
mutate(porcentaje = round(100 * n / sum(n), 2)) # Calcular el porcentaje
categorias_porcentajes %>%
arrange(desc(n)) %>%
gt::gt()| resultado | n | porcentaje |
|---|---|---|
| simple felicidad | 29 | 50.88 |
| educación | 9 | 15.79 |
| logro personal | 7 | 12.28 |
| creatividad | 5 | 8.77 |
| paz | 4 | 7.02 |
| familia | 1 | 1.75 |
| ocio | 1 | 1.75 |
| salud y bienestar | 1 | 1.75 |
La distribución de categorías en la tabla muestra que “simple felicidad” es la emoción más comúnmente reportada, representando el 52.5% de los casos, lo que sugiere que los momentos de felicidad sencilla son especialmente valorados en la muestra. Le sigue “logro personal” con un 13.5%, indicando que los logros individuales también son una fuente significativa de satisfacción. “educación” ocupa el tercer lugar con un 11.8%, destacando la importancia de la fromación. Otras categorías como “creatividad”, “salud y bienestar”, etc tienen una representación menor, lo que sugiere que, aunque estos factores contribuyen al bienestar, son menos predominantes en comparación con las primeras tres categorías.
Visualicemos las frecuencias relativas en un waffle de higcharter:
# Crear el gráfico de waffle
waffle_chart <- categorias_porcentajes %>%
arrange(desc(porcentaje)) %>%
hchart(
type = "item",
hcaes(name = resultado, y = porcentaje, fillColor = resultado),
marker = list(symbol = "square") # Usar cuadrados para el gráfico de waffle
) %>%
hc_colors(c( "#7fb77e","#363b74", "#ef4f91", "#c79dd7",
"#fffdd0", "#7F7F7F", "#8C564B", "#D62728")) %>% # Colores
hc_tooltip(
pointFormat = "<br>{point.percentage:.1f} %<br>"
) %>%
hc_title(text = "<b>Categorias simuladas de felicidad en porcentajes</b>")
# Mostrar el gráfico
waffle_chartSegmentación de relatos
Para concluir esta experiencia aplicada vamos a machear la información obtenida en el punto anterior con los datos originales, lo que nos va permitar visualizar la distribución de las categorías de anhelos entre diferentes grupos.
Analicemos primero cómo estas categorías se distribuyen por género. Este análisis inicial ofrece una oportunidad para detectar diferencias en las formas en que hombres y mujeres expresan sus anhelos y felicidad en los relatos generados. Al observar cómo se comportan estas categorías por género, podemos formular hipótesis sobre cómo ciertas experiencias emocionales se valoran de manera distinta en cada grupo. Aunque los datos son sintéticos, esta aproximación nos proporciona una visión de laboratorio sobre posibles variaciones en las prioridades emocionales entre hombres y mujeres, lo cual podría servir de base para futuros estudios más profundos con datos empíricos.
Enriquecemos los datos originales haciendo un left join:
# Realizar el left_join con las versiones únicas
aperturas <- respuestas_limpias %>%
left_join(data_actualizada)Calculamos las frecuencias y porcentajes por categoría, para cada género:
categorias_sexo <- aperturas %>%
filter(!resultado %in% c("N/A", "")) %>% # Filtrar resultados inválidos
group_by(sexo, resultado) %>% # Agrupar por sexo y categoría
summarise(n = n()) %>% # Contar las ocurrencias
arrange(sexo, desc(n)) # Ordenar por sexo y por número de ocurrencias (n)Finalmente mostramos la data con barras agrupadas:
# Crear el gráfico de barras agrupadas
hc <- categorias_sexo %>%
arrange(desc(n)) %>%
hchart("bar",
hcaes(x = resultado, y = n, group = sexo)
)
# Aplicar colores a las series
hc <- hc %>%
hc_colors(c("#7CB5EC", "#F7A35C")) %>%
hc_title(text = "Frecuencias por sexo y tipo de felicidad simulada") %>%
hc_xAxis(title = list(text = "Resultado")) %>%
hc_yAxis(title = list(text = "Proporción")) %>%
hc_plotOptions(column = list(
dataLabels = list(enabled = TRUE, format = "{point.y:.2f}"),
enableMouseTracking = TRUE
))
# Mostrar el gráfico
hcExaminemos qué pasa con la distribución de las categorías por perfil ocupacional. Este análisis, basado en datos generados artificialmente, nos permite explorar cómo las distintas ocupaciones podrían influir en la forma en que las personas experimentan y describen la felicidad.
El tipo de gráfico generado en este caso podria darnos pistas sobre posibles diferencias en las expresiones emocionales según el tipo de trabajo que desempeñan las personas. Si bien los resultados son simulados, el proceso abre la puerta a investigaciones más específicas que podrían centrarse en las conexiones entre el entorno laboral y las emociones predominantes en las personas.
categorias_ocupacion <- aperturas %>%
filter(!resultado %in% c("N/A", "")) %>% # Filtrar resultados inválidos
group_by(ocupacion, resultado) %>% # Agrupar por sexo y categoría
summarise(n = n()) %>% # Contar las ocurrencias
arrange(ocupacion, desc(n)) # Ordenar por sexo y por número de ocurrencias (n)
# Crear el gráfico de barras agrupadas
hc <- categorias_ocupacion %>%
arrange(desc(n)) %>%
hchart("bar",
hcaes(x = resultado, y = n, group = ocupacion)
)
# Aplicar los colores personalizados a las series
hc <- hc %>%
hc_colors(c("#363b74", "#163999", "#ef4f91", "#c79dd7",
"#6d1b7b", "#7F7F7F", "#8C564B", "#D62728")) %>% # Colores personalizados
hc_title(text = "Frecuencias por ocupación y tipo de felicidad simulada") %>%
hc_xAxis(title = list(text = "Resultado")) %>%
hc_yAxis(title = list(text = "Proporción")) %>%
hc_plotOptions(column = list(
dataLabels = list(enabled = TRUE, format = "{point.y:.2f}"),
enableMouseTracking = TRUE
))
# Mostrar el gráfico
hcLa distribución por ocupación, organizada en un gráfico de barras agrupadas, facilita una rápida comprensión de cómo cada perfil podría priorizar distintas emociones o experiencias, generando una base para investigar más a fondo acerca de cómo el trabajo influye en las percepciones de felicidad.
Resultados preliminares
A pesar de los desafíos iniciales y los resultados no del todo óptimos, este experimento basado en modelos de lenguaje de gran escala (LLMs) ha abierto nuevas posibilidades para futuras investigaciones en ciencias sociales. Aunque el modelo enfrentó dificultades en la clasificación y etiquetado de textos, mostrando inconsistencias en algunas respuestas y clasificaciones generales, estos problemas son comunes en las primeras fases de innovaciones tecnológicas. Lejos de ser percibidos como fallas, deben interpretarse como oportunidades para iterar y mejorar las herramientas, explorando su aplicación en contextos más complejos.
Cada avance tecnológico pasa por etapas de perfeccionamiento, y lo mismo sucede con el uso de la inteligencia artificial en ciencias sociales. Uno de los aspectos más prometedores es el potencial de los LLMs para automatizar tareas que tradicionalmente requerían considerable esfuerzo manual. El valor de estos resultados preliminares no está en su perfección, sino en el camino que abren hacia mejoras continuas. Estamos en una posición privilegiada para identificar áreas clave en las que estos modelos pueden desarrollarse y optimizarse.
La experiencia ha revelado el inmenso potencial de los LLMs para potenciar la investigación social. En lugar de depender únicamente de la intervención humana para analizar grandes volúmenes de texto, podemos imaginar un futuro en el que estos modelos desempeñen un rol central en la identificación de patrones y relaciones en el lenguaje, proporcionando una comprensión más profunda de fenómenos sociales complejos.
A medida que ajustamos y perfeccionamos estos sistemas, su capacidad para interpretar textos con mayor precisión y en contextos más diversos seguirá creciendo. Este proceso de experimentación convierte a los LLMs en herramientas esenciales para los científicos sociales, permitiendo un análisis más eficiente, detallado y riguroso.
Aunque aún nos encontramos en las etapas iniciales de la integración entre inteligencia artificial y ciencias sociales, lo que hemos observado hasta ahora es una gran promesa de innovación. Cada error es una oportunidad para aprender y avanzar. El futuro de la investigación social asistida por IA es brillante, y los próximos pasos serán fundamentales para desbloquear todo su potencial.
Hasta la próxima!
🚀
Footnotes
En la clase presencial se trabajó originalmente con un caso de encuesta real.↩︎
Ver Inteligencia artificial: definiciones en disputa (2020)↩︎
Es decir el input que le damos a un LLM para guiar la forma en que responde o actúa. La precisión y claridad del prompt pueden influir significativamente en la calidad de la respuesta que se obtiene del modelo.↩︎
Reuse
Citation
BibTeX citation:
@online{damian_orden2024,
author = {Damian Orden, Pedro},
title = {Explorando Los Usos de La {IA} Generativa En La
{Investigación} {Social}},
date = {2024-09-16},
url = {https://tecysoc.netlify.app/posts/llm aplicado/},
langid = {en}
}
For attribution, please cite this work as:
Damian Orden, Pedro. 2024. “Explorando Los Usos de La IA
Generativa En La Investigación Social.” September 16, 2024. https://tecysoc.netlify.app/posts/llm
aplicado/.